



Scikit-Learn (Parte 3)
Validación, GridSearch y buenas prácticas avanzadas: cómo evaluar modelos sin engañarte a ti mismo
En las Partes 1 y 2 construimos los cimientos:
- entendiste Estimators, Transformers y Predictors
- aprendiste a encadenarlos en un Pipeline real
- evitaste leakage y mantuviste consistencia entre train y test
Ahora toca la parte que separa un notebook bonito de un sistema de ML honesto y fiable:
la validación y el tuning de modelos.
Porque entrenar un modelo es fácil. Evaluarlo bien es lo difícil. Y casi todo el mundo lo hace mal sin darse cuenta.
Vamos paso a paso.
1. El problema: la validación ingenua
Muchos tutoriales hacen esto:
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_test, y_pred)Funciona, sí. Pero tiene problemas serios:
- depende demasiado de un único split
- no detecta la variabilidad del modelo
- no te dice si tu modelo es estable
- no te dice si tu modelo generaliza
- y si hiciste preprocesamiento fuera del Pipeline → leakage garantizado
Piénsalo así: un solo split te da un solo número. Y un solo número no tiene contexto. ¿Ese 0.91 de accuracy es real, o te tocó un test set fácil por azar? No tienes forma de saberlo.
La validación correcta no es un paso final. Es parte del diseño del sistema.
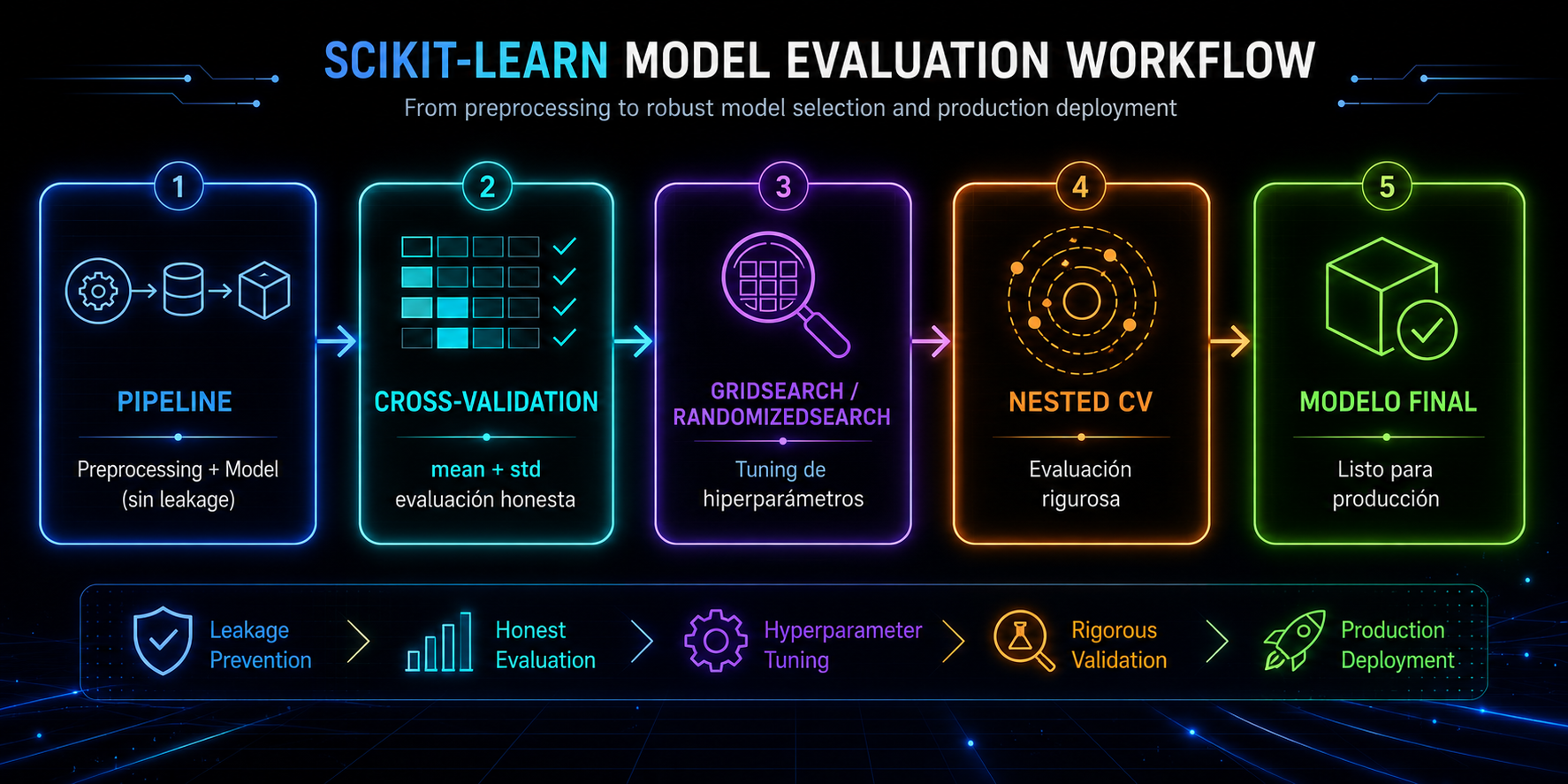
2. Cross-Validation: la base de una evaluación honesta
La validación cruzada (CV) divide los datos en varios folds y repite el entrenamiento varias veces, rotando cuál fold se usa para validar.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(pipeline, X, y, cv=5)
scores.mean(), scores.std()¿Por qué es tan importante?
- reduce la varianza de la evaluación
- detecta modelos inestables
- evita depender de un único split
- evalúa el preprocesamiento dentro del Pipeline
- evita leakage automáticamente
Y fíjate en un detalle que casi nadie mira:scores.std().
La media te dice cómo de bueno es tu modelo. La desviación estándar te dice cómo de fiable es esa media. Dos modelos conmean = 0.88no son iguales si uno tienestd = 0.01y el otrostd = 0.09. El segundo es una montaña rusa: en producción te puede dar 0.79 cualquier día.
Si no usas CV, no estás evaluando tu modelo. Estás jugando a la lotería.
3. StratifiedKFold y la elección del scoring
Dos detalles que marcan la diferencia entre una validación de juguete y una seria.
Estratificación. En clasificación, si tus clases están desbalanceadas (90% A, 10% B), un KFold normal puede dejarte un fold casi sin ejemplos de la clase B. Scikit-Learn lo sabe y, para clasificadores,cross_val_scoreya usaStratifiedKFoldpor defecto. Pero conviene hacerlo explícito cuando controlas el split:
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(pipeline, X, y, cv=cv)La métrica.accuracyes engañosa con clases desbalanceadas: un modelo que siempre predice la clase mayoritaria puede sacar 90% y ser inútil. Elige la métrica según el problema:
scores = cross_val_score(pipeline, X, y, cv=5, scoring='f1_macro')Algunas opciones según el caso:
f1_macro/balanced_accuracy→ clases desbalanceadasroc_auc→ ranking y probabilidadesneg_root_mean_squared_error→ regresiónprecision/recall→ cuando un tipo de error duele más que otro
La pregunta correcta no es «¿qué accuracy tengo?», sino «¿qué error me cuesta dinero?».
4. GridSearchCV: tuning sin romper el Pipeline
El tuning manual es lento, frágil y propenso a errores.GridSearchCVautomatiza la búsqueda de hiperparámetros y lo hace dentro del Pipeline, así que no hay leakage.
from sklearn.model_selection import GridSearchCV
params = {
'prep__num__with_mean': [True, False],
'model__C': [0.1, 1, 10]
}
grid = GridSearchCV(pipeline, params, cv=5)
grid.fit(X, y)La magia está en la sintaxis:
prep__num__with_mean
Que se lee así:
pipeline → paso 'prep' → bloque 'num' → parámetro 'with_mean'
Dobles guiones bajos (__) para bajar de nivel. Con esto puedes tunear el preprocesamiento, el modelo o cualquier paso del Pipeline, todo en una sola llamada y sin leakage.
Pero ojo con el coste. GridSearch prueba todas las combinaciones, y eso se multiplica rápido:
2 (with_mean) × 3 (C) × 5 (folds) = 30 entrenamientos
Añade un tercer parámetro con 4 valores y ya vas por 120. Es la explosión combinatoria: con grids grandes, GridSearch se vuelve impagable.
Cuando termina, lo útil está aquí:
grid.best_params_ # la mejor combinación
grid.best_score_ # su score en CV
grid.best_estimator_ # el Pipeline ya reentrenado con todo X5. RandomizedSearchCV: tuning inteligente
GridSearch prueba todas las combinaciones. RandomizedSearch prueba solo algunas, pero bien elegidas, muestreando de distribuciones que tú defines.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
params = {
'model__C': uniform(0.01, 10)
}
search = RandomizedSearchCV(pipeline, params, n_iter=20, cv=5)
search.fit(X, y)Ventajas:
- más rápido
- más eficiente
- ideal para espacios grandes
- evita combinaciones inútiles
La clave está enn_iter: tú decides cuánto presupuesto gastar. En vez de probarlo todo, fijas 20 intentos y dejas que el azar explore. En espacios de hiperparámetros amplios, RandomizedSearch suele encontrar algo casi tan bueno como GridSearch en una fracción del tiempo.
Regla práctica: grid pequeño y discreto → GridSearch. Espacio grande o continuo → RandomizedSearch.
6. Nested Cross-Validation: la evaluación definitiva
Aquí está la trampa que casi nadie ve: si usas el mismo CV para elegir los hiperparámetros y para reportar el resultado, estás haciendo trampa sin querer. Has optimizado contra esos folds, así que ese score ya está contaminado, es optimista.
La solución es nested CV (CV anidado):
- CV externo → evalúa el modelo
- CV interno → hace el GridSearch
from sklearn.model_selection import cross_val_score, KFold
outer = KFold(n_splits=5)
scores = cross_val_score(grid, X, y, cv=outer)Lo que pasa por dentro: en cada fold externo, elgridhace su propia búsqueda de hiperparámetros usando solo el train de ese fold, y luego se evalúa en el test externo, que nunca vio durante el tuning. Resultado: un score honesto, sin que los hiperparámetros se hayan ajustado al conjunto de evaluación.
Es más caro (un GridSearch completo por cada fold externo), pero es lo que se usa en papers, benchmarks y producción seria.
7. Buenas prácticas avanzadas
✔️ 1. Todo lo que aprende de los datos → dentro del Pipeline. Scaler, PCA, imputación, encoding… todo. Si se ajusta a los datos, va dentro.
✔️ 2. Nunca usesfit_transformfuera del Pipeline. Es la forma más común de leakage, y la más silenciosa.
✔️ 3. Evalúa siempre con CV. Un único split no es suficiente. Y mira lastd, no solo la media.
✔️ 4. Tunea hiperparámetros dentro del Pipeline. No fuera. El preprocesamiento también tiene parámetros que tunear.
✔️ 5. Usa la métrica correcta.accuracyno sirve con clases desbalanceadas.
✔️ 6. Guarda el Pipeline completo, no el modelo. El modelo sin preprocesamiento no sirve en producción.
8. Ejemplo final: evaluación + tuning + producción
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
preprocess = ColumnTransformer([
('num', StandardScaler(), ['age', 'salary']),
('cat', OneHotEncoder(handle_unknown='ignore'), ['city', 'gender'])
])
pipeline = Pipeline([
('prep', preprocess),
('model', LogisticRegression())
])
params = {
'model__C': [0.1, 1, 10]
}
grid = GridSearchCV(pipeline, params, cv=5, scoring='f1_macro')
grid.fit(X, y)
best_model = grid.best_estimator_Y lo guardas:
import joblib
joblib.dump(best_model, 'pipeline.pkl')Esto ya es nivel producción. Validado, tuneado, con la métrica correcta y listo para desplegar como un único objeto.
TL;DR
- La validación correcta es parte del diseño, no un paso final.
- Cross-Validation es obligatorio para evaluar modelos de forma honesta, y la
stdimporta tanto como la media. - Usa StratifiedKFold y la métrica adecuada;
accuracyengaña con clases desbalanceadas. - GridSearchCV prueba todo (cuidado con la explosión combinatoria); RandomizedSearchCV explora con presupuesto fijo.
- Nested CV es la evaluación más rigurosa: separa elegir hiperparámetros de reportar resultados.
- Todo el preprocesamiento debe vivir dentro del Pipeline.
- Lo que despliegas no es un modelo: es un Pipeline completo.