



Regresión Lineal
O cómo trazar la mejor raya entre un montón de puntos
Seguro que alguna vez has mirado una gráfica y has pensado: «está claro que esto sube». Pues enhorabuena: tu cerebro acaba de hacer, a ojo, una regresión lineal.
La Regresión Lineal es exactamente eso: encontrar la línea recta que mejor resume una nube de puntos. Es lo primero que aprende casi todo el que entra en el mundo del Machine Learning, y por eso mucha gente la descarta pensando que es «demasiado fácil».
Gran error. Porque esta humilde recta esconde casi todas las ideas que después mueven a los modelos más avanzados:
- la idea de aprender de los datos ajustando unos pocos números,
- la de medir cuánto nos equivocamos,
- la de mejorar poco a poco ese error,
- y la base sobre la que se construyen las redes neuronales y el deep learning.
Por eso suele decirse algo que no es ninguna exageración:
Si entiendes bien la Regresión Lineal, tienes medio camino hecho en el ML clásico.
Vamos despacio y sin prisas.
1. ¿Qué problema resuelve?
Imagina que tienes una tabla con dos columnas. En una apuntas algo que conoces (las horas que alguien estudió, el tamaño de un piso, la temperatura de un día). En la otra, algo que quieres adivinar (la nota del examen, el precio del piso, las ventas de helados).
La pregunta es siempre la misma:
«Si conozco la primera columna, ¿puedo predecir la segunda?»
La Regresión Lineal responde con la solución más sencilla posible: trazar una raya recta que conecte ambas cosas. Una vez tienes esa raya, predecir es trivial: pones tu dato de entrada, miras dónde cae la línea y ahí está tu predicción.
Esa raya tiene solo dos mandos que la controlan:
- uno la sube o la baja entera,
- otro la inclina más o menos.
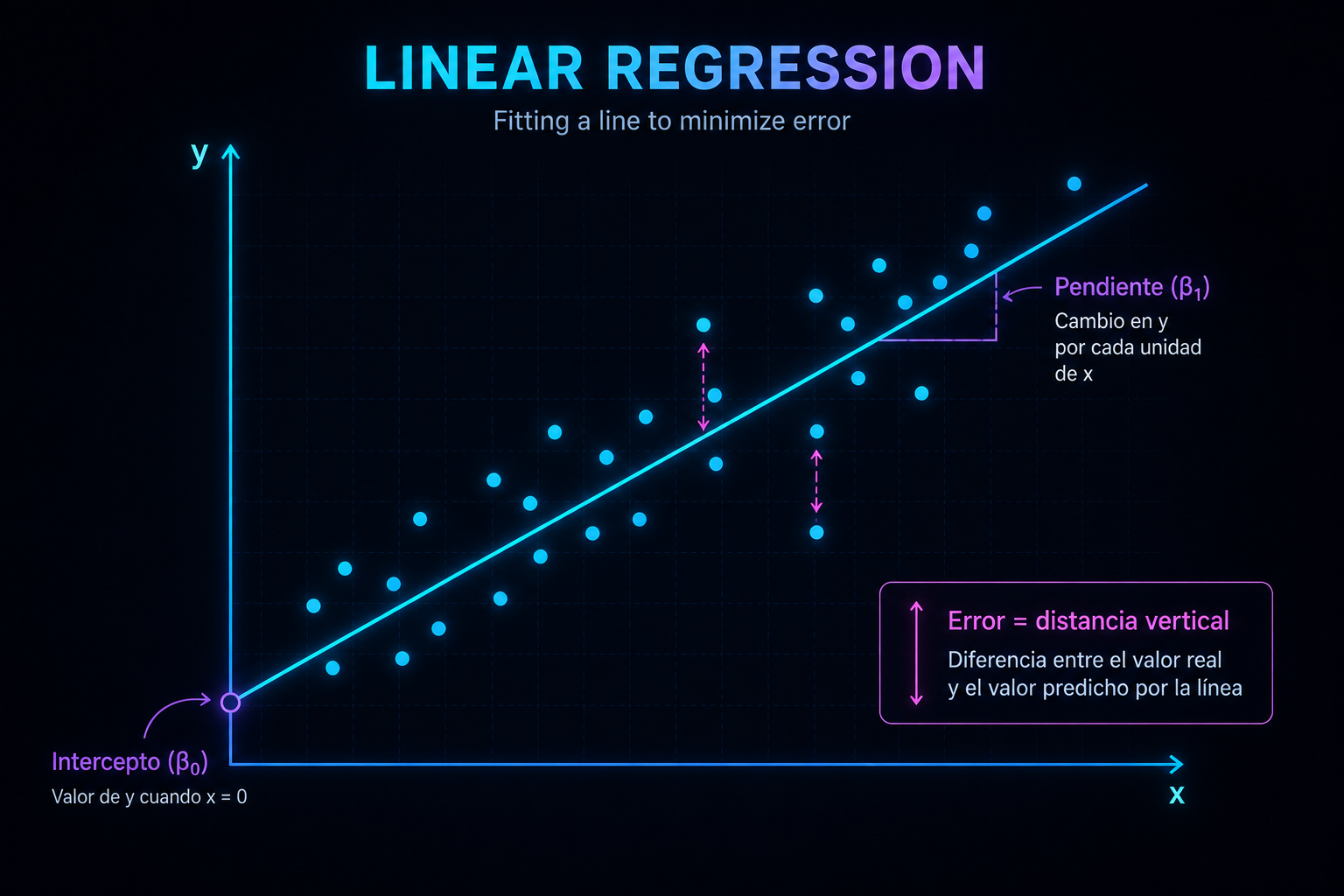
Y ya está. Ajustando esos dos mandos puedes colocar la recta en cualquier posición. Los matemáticos los llaman intercepto y pendiente, y los escriben así:
ŷ = β₀ + β₁·x
No te asustes con los símbolos: β₀ es el mando que sube y baja, β₁ es el que inclina, y ŷ es simplemente la predicción que sale al final. Volveremos a ellos.
2. La idea clave: que ningún punto quede demasiado lejos
Aquí está el corazón de todo, y se entiende mucho mejor con una imagen mental.
Imagina tus datos como un montón de puntos desperdigados sobre un papel. Tu misión es dibujar una raya recta que pase «entre todos ellos». El problema es que ninguna recta pasará por todos a la vez: algunos puntos quedarán por encima de tu línea y otros por debajo.
A esa distancia que sobra entre un punto y la raya la llamamos error: es lo que el modelo se equivoca con ese punto concreto.
La regresión busca la raya que deja a todos los puntos lo más cerca posible. Pero hay un detalle astuto en cómo mide esa cercanía: en lugar de sumar las distancias tal cual, las eleva al cuadrado.
¿Por qué ese truco? Por tres razones muy intuitivas:
- Hace que los fallos gordos duelan más. Un punto que se queda muy lejos penaliza muchísimo, así que el modelo se esfuerza de verdad en no abandonar a nadie en mitad de la nada.
- Evita que los errores se anulen entre sí. Sin el cuadrado, un punto muy por encima y otro muy por debajo se compensarían y darían una falsa sensación de «todo va bien».
- Hace las cuentas más fáciles para que el ordenador pueda encontrar la mejor recta de forma limpia.
Este método de «elegir la raya que minimiza los errores al cuadrado» tiene un nombre rimbombante: Mínimos Cuadrados Ordinarios. Pero la idea, como ves, es de andar por casa.
3. La pendiente: el dato más útil del modelo
De los dos mandos de la recta, la pendiente (esa β₁) es el más interesante, porque te cuenta una historia en lenguaje humano:
«Por cada unidad que sube la entrada, la predicción se mueve esto.»
Vamos con un ejemplo de la vida real. Imagina que entrenamos el modelo con datos de estudio y resulta que la pendiente vale 0,5. La traducción es:
Por cada hora extra que estudias, tu nota sube medio punto.
Así de simple y así de potente. Si la pendiente fuera un número negativo, la historia sería al revés: cuando una cosa sube, la otra baja (por ejemplo, cuantas más horas de móvil antes de dormir, menos horas de sueño).
Esto es lo que hace a la Regresión Lineal tan especial frente a modelos más «caja negra»: no solo te da un número, sino que te explica la relación entre las cosas. Es un modelo que se puede leer y entender.
4. ¿Y el otro mando, el que sube y baja?
El intercepto (β₀) es simplemente la altura de partida de la recta: el valor que predice el modelo cuando la entrada vale cero.
Su trabajo es permitir que la línea se coloque a la altura correcta. Sin él, obligaríamos a la raya a salir siempre desde el suelo (el punto cero), y eso casi nunca encaja con los datos reales.
Eso sí, una advertencia honesta: el intercepto no siempre significa algo en el mundo real. Si tu entrada es el tamaño de una casa, un piso de «cero metros cuadrados» no existe, así que su predicción no tiene sentido práctico. Pero el modelo lo necesita igualmente para funcionar bien. Piénsalo como una pieza interna del mecanismo: no siempre la miras, pero sin ella la máquina cojea.
5. ¿Cómo encuentra el ordenador la mejor recta?
Vale, ya sabemos qué queremos: la raya con el menor error posible. ¿Pero cómo la encuentra la máquina? Hay dos formas, y las dos merece la pena conocerlas.
La vía rápida: la fórmula mágica.
Para la Regresión Lineal existe una fórmula matemática que escupe la recta perfecta de un solo cálculo, sin tanteos. Es como tener la solución de un sudoku impresa al lado: directa y exacta. Las librerías típicas (como Scikit-Learn) la usan siempre que pueden, porque es rápida y precisa.
La vía paso a paso: probar y corregir.
La segunda forma es más artesanal: el ordenador empieza con una raya cualquiera, mira cuánto se equivoca, la ajusta un poquito, vuelve a mirar, la ajusta otra vez… y así hasta que el error es mínimo. Es como afinar una guitarra: vas girando la clavija poco a poco hasta que la cuerda suena bien.
Esta segunda vía tiene un nombre, descenso del gradiente, y aunque parezca la menos elegante, es muchísimo más importante a largo plazo: es el motor que mueve casi todo el ML moderno, desde las redes neuronales hasta el deep learning.
En la Parte 2 veremos cómo el modelo mide exactamente su error.
En la Parte 3 desmontaremos el «afinado» paso a paso.
6. ¿Por qué sigue importando tanto un modelo tan viejo?
Por dos motivos: por todo lo que te enseña y por todo lo que se sigue usando.
Como primer modelo, es una clase magistral disfrazada de cosa sencilla. Aprendiéndolo, entiendes de golpe ideas que aparecen en todo el campo: cómo un modelo aprende de los datos, cómo se mide un error, cómo se mejora, cómo se interpreta un resultado e incluso cómo empiezan los problemas cuando un modelo «se aprende los datos de memoria».
Y como herramienta real, está lejísimos de ser una reliquia de manual. Ahora mismo se usa para:
- predecir ventas y demanda en empresas,
- fijar precios,
- entender qué causa qué en estudios y análisis,
- alimentar modelos económicos,
- y formar parte de sistemas de predicción más grandes.
Por eso muchos lo llaman el modelo más subestimado del Machine Learning: tan simple que se ignora, tan fundamental que está en todas partes.
En resumen
- La Regresión Lineal busca la raya que deja a todos los puntos lo más cerca posible.
- Lo consigue castigando más los errores grandes (por eso eleva las distancias al cuadrado).
- La pendiente te cuenta cuánto se mueve la predicción cuando cambia el dato de entrada; es lo que hace al modelo fácil de interpretar.
- El intercepto coloca la raya a la altura correcta.
- El ordenador encuentra esa raya con una fórmula directa o probando y corrigiendo poco a poco.
- Entenderla bien es entender la base de casi todo el Machine Learning.