



Regresión Lineal (Parte 4)
Actualización de coeficientes: cómo se ajustan β₀ y β₁ en cada paso
En la Parte 3 vimos el corazón del aprendizaje: el Descenso del Gradiente. Entendimos la idea de bajar por el valle, la brújula que es el gradiente y la importancia de la tasa de aprendizaje. Pero dejamos una pregunta colgando en el aire, y es precisamente la que convierte toda esa teoría en algo que de verdad funciona:
¿Cómo se actualizan exactamente los coeficientes del modelo?
Porque hasta ahora hemos hablado en términos generales. Sabemos que el gradiente nos dice la dirección en la que movernos y que la tasa de aprendizaje nos dice el tamaño del paso. Pero todavía no hemos visto las fórmulas concretas, las que el ordenador ejecuta una y otra vez, miles de veces, para que la recta deje de ser un disparate y empiece a encajar con los datos.
Hoy cerramos ese círculo. Y verás que, cuando lo desmontamos pieza a pieza, no hay nada mágico: solo dos pequeñas restas que se repiten hasta que el error deja de bajar.
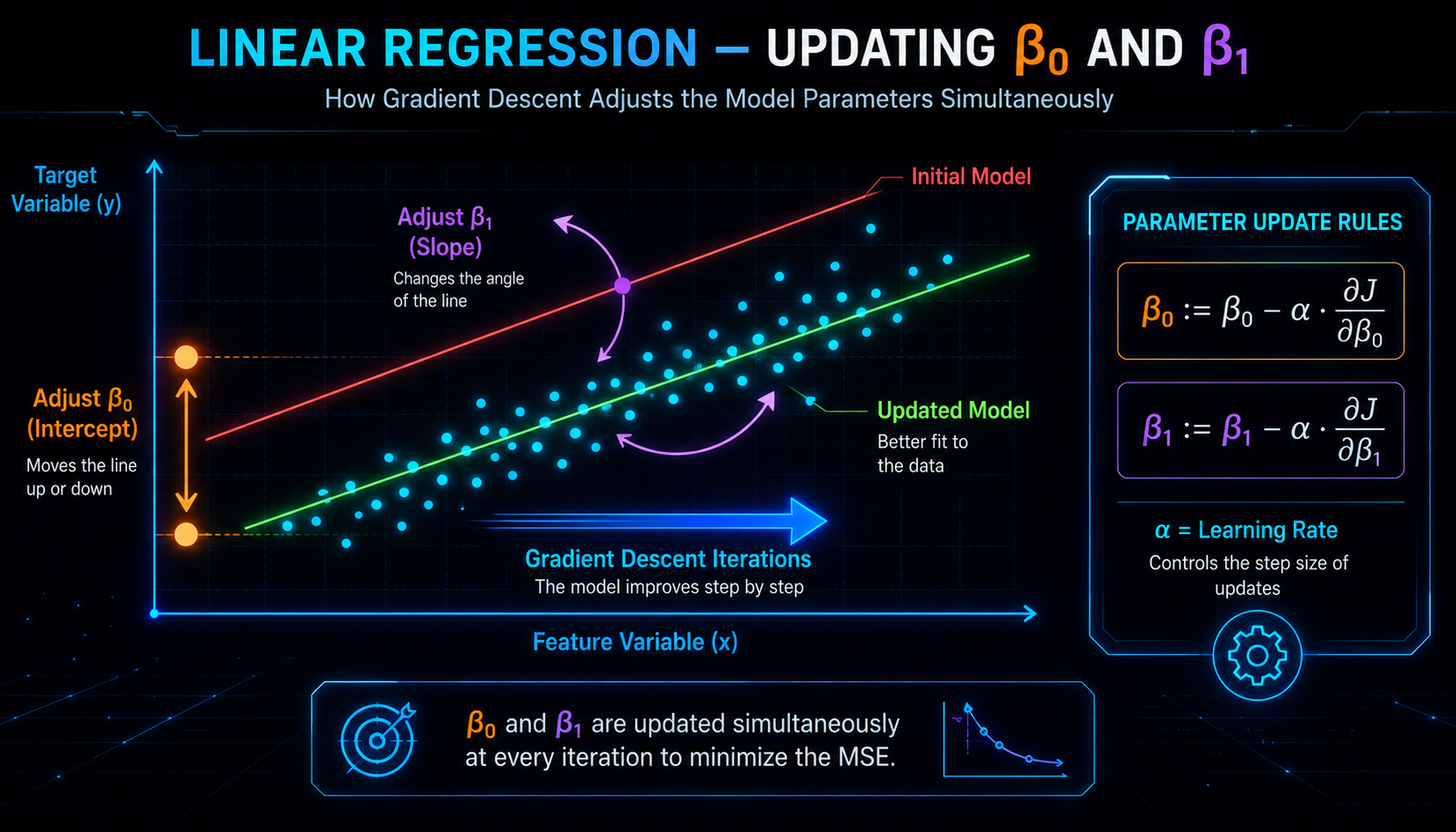
1. Recordatorio rápido: de dónde venimos
Antes de tocar las fórmulas de actualización, recordemos las dos piezas que ya conocemos, porque todo lo demás se construye encima de ellas.
La predicción en regresión lineal simple es nuestra recta de toda la vida:
Donde es el punto donde la recta corta el eje vertical (el intercepto) y es su pendiente, cuánto sube la recta por cada unidad que avanzamos en x.
Y la forma de medir lo mal que lo estamos haciendo es el error cuadrático medio (MSE), que vimos en la Parte 2:
La clave está aquí: para mejorar el modelo necesitamos saber cómo cambia ese error cuando movemos un poquito o . Y «cómo cambia algo cuando movemos otra cosa un poquito» es, ni más ni menos, la definición de una derivada. Por eso el siguiente paso es calcular las derivadas parciales del MSE respecto a cada coeficiente. No te preocupes si la palabra «derivada» te impone: lo que importa no es el cálculo, sino lo que cada derivada nos está diciendo.
2. Derivada respecto a β₀: el ajuste de altura
La derivada del MSE respecto a es:
Olvidemos por un momento la notación y quedémonos con lo esencial: esta fórmula no es más que el promedio de todos los errores (multiplicado por 2). Es decir, suma todas las veces que te has pasado y todas las veces que te has quedado corto, y mira hacia qué lado se inclina la balanza en conjunto.
¿Qué nos dice eso en la práctica?
- Si tus predicciones están, en promedio, por encima de los valores reales, esta suma es positiva, así que el modelo bajará para corregir.
- Si están en promedio por debajo, la suma es negativa y el modelo subirá .
La idea intuitiva es que controla la altura de la recta: la desplaza entera hacia arriba o hacia abajo, sin cambiar su inclinación. Imagina una barra horizontal flotando sobre tus datos; ajustar es subirla o bajarla en bloque hasta que quede centrada entre los puntos. Por eso solo le importa el error promedio, sin fijarse en dónde están los puntos en el eje x.
3. Derivada respecto a β₁: el ajuste de inclinación
La derivada respecto a se parece mucho a la anterior, pero con un detalle crucial:
¿Ves la diferencia? Cada error aparece multiplicado por su . Ese pequeño lo cambia todo, porque hace que los errores pesen de forma distinta según dónde estén.
La intuición es la siguiente: los puntos que están lejos en el eje x (con un valor de grande) tienen mucha más capacidad de «hacer girar» la recta. Piensa en una palanca: cuanto más lejos del punto de apoyo empujas, más giro consigues con menos fuerza. Aquí pasa igual. Un error en un punto lejano arrastra la pendiente con mucha más fuerza que el mismo error en un punto cercano al origen.
Por eso decimos que controla la inclinación de la recta. Mientras sube y baja la recta entera, la hace girar para que su ángulo siga la tendencia de los datos.
4. Las fórmulas finales de actualización
Ahora juntamos las dos piezas. Recuerda la regla del Descenso del Gradiente de la Parte 3: nuevo valor = valor actual − (tasa de aprendizaje) × (pendiente del error). Sustituyendo las derivadas que acabamos de calcular, obtenemos las dos ecuaciones que son el verdadero motor del entrenamiento:
Y aquí viene lo importante, lo que conviene que se te quede grabado: esto es todo. No hay más. Estas dos restas, ejecutadas a la vez en cada iteración, son literalmente lo que un modelo de regresión lineal hace para aprender.
Un detalle que suele pasar desapercibido pero que es fundamental: ambos coeficientes se actualizan al mismo tiempo, usando los valores «viejos» de y . No actualizas y luego usas ese valor nuevo para . Calculas los dos ajustes con la recta actual y luego das los dos pasos a la vez. Es como ajustar el volumen y los graves de un equipo de música: mueves ambos a partir de cómo suena ahora, no encadenas uno con otro.
5. Intuición geométrica: ajustar una regla sobre la mesa
Si las fórmulas todavía te parecen abstractas, esta es probablemente la mejor imagen mental que puedes tener.
Imagina que tienes una mesa cubierta de puntos y una regla larga que quieres colocar de forma que pase lo más cerca posible de todos ellos. ¿Qué haces de manera natural?
- Primero la subes o la bajas en bloque, para que quede más o menos a la altura de la nube de puntos. Eso es ajustar .
- Luego la giras un poco, para que su inclinación siga la tendencia de los datos. Eso es ajustar .
- Miras cómo ha quedado, ves que aún no es perfecto, y vuelves a corregir la altura y el ángulo.
- Repites una y otra vez, con ajustes cada vez más finos, hasta que la regla queda en la posición más equilibrada posible.
Eso es exactamente lo que hacen las dos fórmulas anteriores en cada iteración: una empuja la recta arriba o abajo, la otra la inclina, y juntas la van acercando a los datos paso a paso. Lo que para nosotros es ojo y mano, para el modelo son dos restas.
6. Ejemplo numérico paso a paso
Nada aclara más que ver los números moverse de verdad. Vamos a hacer una iteración completa con un solo punto, para no perdernos. (Para que sea más fácil de seguir, simplificamos dejando el factor de escala fuera y trabajando con un único dato; la lógica es idéntica.)
Partimos de un modelo que arranca con valores cualesquiera:
- Tasa de aprendizaje:
- Nuestro punto: ,
Paso 1 — Predecimos con la recta actual:
Paso 2 — Medimos el error. El valor real era 10, pero predijimos 7:
El error es negativo, lo que significa que nos hemos quedado cortos: la recta predice por debajo de la realidad.
Paso 3 — Actualizamos los coeficientes:
¿Y qué ha pasado? La recta ha subido ( pasó de 1 a 1.3) y se ha inclinado más ( pasó de 2 a 2.9). Y tiene todo el sentido del mundo: como estábamos prediciendo demasiado bajo, el modelo reacciona levantando la recta y aumentando su pendiente para acercarse a ese punto que se le había escapado por arriba.
Si ahora volviéramos a predecir con los nuevos coeficientes, el error sería más pequeño. Repite esto miles de veces, con todos tus puntos, y tienes un modelo entrenado.
7. ¿Cuándo paramos de actualizar?
Una pregunta lógica: si el modelo repite estas restas una y otra vez, ¿cuándo decide que ya es suficiente? Hay tres señales habituales para detenerse, y normalmente se usan combinadas:
- El error apenas cambia. Si entre una iteración y la siguiente la mejora es minúscula, seguir es malgastar tiempo de cálculo.
- El gradiente es casi cero. Recuerda de la Parte 3 que el gradiente se aplana al acercarse al fondo del valle. Cuando es prácticamente cero, significa que ya estamos en el punto más bajo y no hay hacia dónde bajar.
- Se alcanza un número máximo de iteraciones. Un límite de seguridad que fijamos nosotros para que el proceso no se eternice.
Y aquí conviene recordar la gran tranquilidad de la regresión lineal: gracias a que su superficie de error es convexa (esa forma de cuenco que vimos en la Parte 2), sabemos que siempre llegaremos al mismo mínimo global, sin importar con qué valores arrancáramos. No existe el riesgo de quedarse atrapado en un «valle falso». En modelos más complejos, como las redes neuronales, esto ya no está garantizado, y por eso allí parar en el momento adecuado se vuelve todo un arte.
8. La misma fórmula para Batch, SGD y Mini‑batch
Quizá te preguntes cómo encajan estas fórmulas con las variantes del Descenso del Gradiente que mencionamos al final de la Parte 3. La respuesta es bonita por lo sencilla: las fórmulas no cambian en absoluto. Lo único que cambia es cuántos errores metes dentro de esa suma antes de actualizar.
| Variante | Cuántos puntos usa en la suma |
|---|---|
| Batch GD | Suma el error de todos los datos antes de cada actualización. |
| SGD | Suma el error de un solo punto y actualiza de inmediato. |
| Mini‑batch | Suma el error de un pequeño lote (32, 64, 128…) y actualiza. |
Es decir, el ejemplo que hicimos en la sección 6 con un solo punto es, técnicamente, un paso de SGD. Si en lugar de un punto hubiéramos promediado el error de los mil puntos del conjunto, sería Batch. Y si hubiéramos usado un grupito de 64, Mini‑batch. El mecanismo de actualización, las dos restas, es siempre idéntico. Eso es lo elegante: una vez entiendes la fórmula, entiendes las tres variantes de golpe.
En resumen
- y se actualizan usando las derivadas del MSE, que no son más que el error promedio (para ) y el error ponderado por x (para ).
- ajusta la altura de la recta; ajusta su inclinación, y los puntos lejanos tienen más fuerza para girarla.
- Las fórmulas de actualización son dos simples restas basadas en el gradiente, aplicadas a la vez en cada iteración.
- Cada paso mueve la recta un poco más cerca de los datos, como quien ajusta una regla sobre una mesa.
- Gracias a la convexidad, siempre llegamos al mismo mínimo global.
- Y lo más importante: este mecanismo tan sencillo es la misma base sobre la que aprenden modelos mucho más complejos, desde la regresión logística hasta las redes neuronales.