



Regresión Lineal (Parte 3)
Descenso del Gradiente: el algoritmo que enseña al modelo a aprender
En la Parte 1 dibujamos la recta. En la Parte 2 aprendimos a medir cuánto se equivocaba. Ahora llega la pregunta que lo conecta todo:
¿Cómo mejora de verdad el modelo?
Porque conocer el error no basta. Un modelo solo se vuelve útil cuando es capaz de reducir ese error de forma sistemática. Y la herramienta que lo consigue es uno de los algoritmos más importantes de todo el Machine Learning:
⭐ El Descenso del Gradiente
Vamos paso a paso, sin prisa, porque entender bien esta idea es entender cómo aprende casi cualquier modelo moderno.
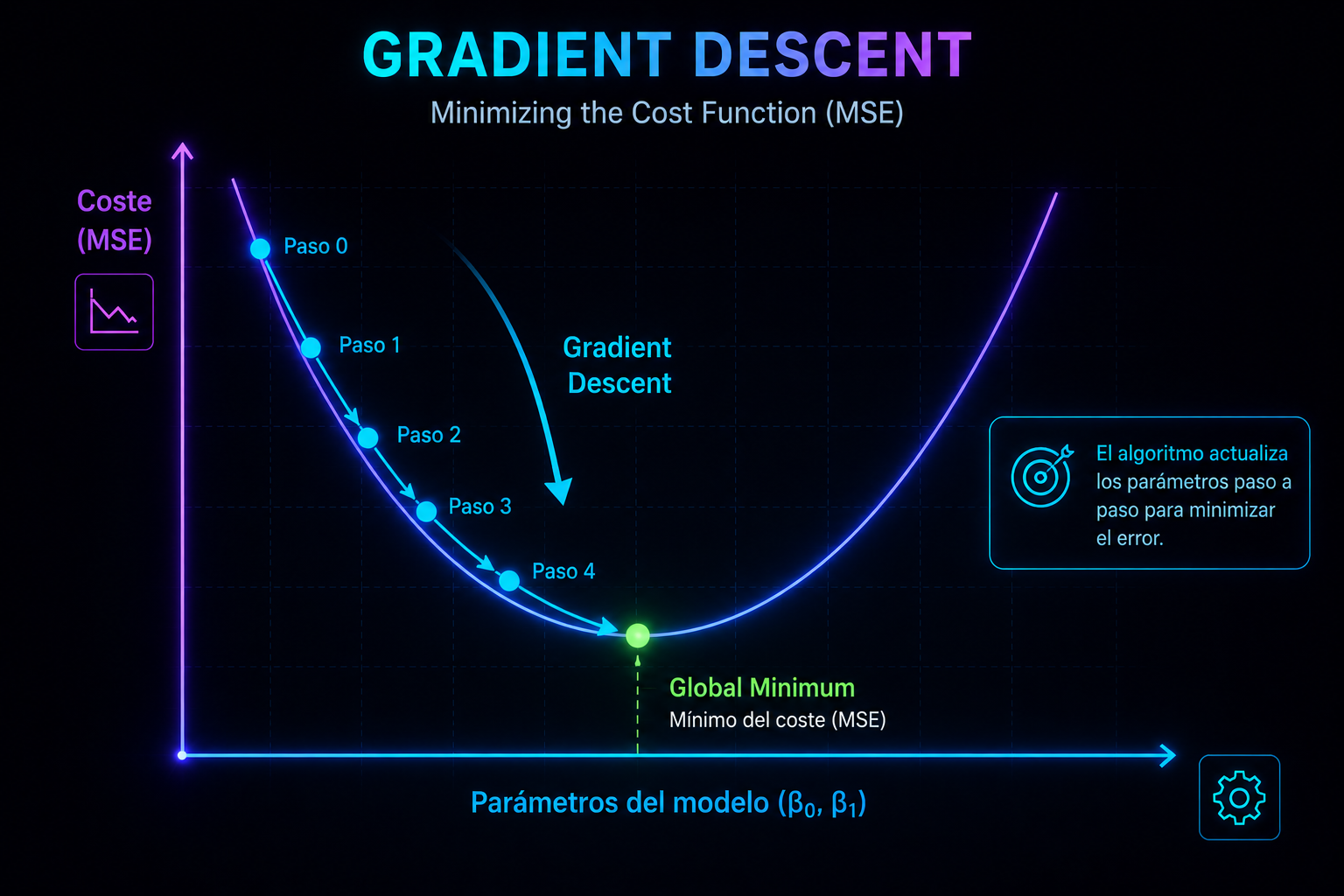
1. El objetivo: encontrar el fondo del valle
Recupera la imagen de la Parte 2: la función de coste (el MSE) era un paisaje suave en forma de cuenco.
- Los ejes horizontales representan los parámetros del modelo: (intercepto) y (pendiente).
- El eje vertical representa el error, el MSE.
- El fondo del cuenco es el mínimo global: la combinación de parámetros que produce la mejor recta posible.
El Descenso del Gradiente no es nada más (ni nada menos) que el algoritmo que baja por ese paisaje hasta llegar al punto más bajo. Todo lo que viene a continuación son los detalles de cómo da cada paso.
2. El gradiente: la brújula que apunta cuesta arriba
Antes de moverse, el modelo necesita responder a una pregunta muy concreta:
Si cambio un poquito o , ¿el error sube o baja? ¿Y cuánto?
Esa información es exactamente lo que da el gradiente. Matemáticamente es un vector formado por las derivadas parciales de la función de coste respecto a cada parámetro:
Pero en lenguaje humano la idea es muy sencilla:
El gradiente te dice hacia dónde aumenta el error más rápido, y con qué intensidad.
Aquí está el detalle elegante: como nosotros queremos justo lo contrario, disminuir el error, basta con movernos en la dirección opuesta al gradiente. El gradiente apunta cuesta arriba; nosotros caminamos cuesta abajo.
3. La regla de actualización: dar un paso cuesta abajo
Una vez conocemos el gradiente, la regla para mejorar es sorprendentemente corta:
Donde:
- es el parámetro que estamos ajustando ( o ),
- es la tasa de aprendizaje (el tamaño del paso),
- es la pendiente del error respecto a ese parámetro.
En cristiano, la fórmula dice esto:
Valor nuevo = valor actual − (pendiente del error) × (tamaño del paso)
Y ya está. Eso es el algoritmo completo. Lo único que hace el modelo es aplicar esta resta una y otra vez, ajustando y a la vez, hasta que el error deja de bajar.
Un detalle bonito de esta fórmula: la pendiente actúa como freno automático. Cuando estás lejos del fondo, la pendiente es grande y los pasos son largos; a medida que te acercas al mínimo, la pendiente se aplana, los pasos se acortan solos y el modelo «aterriza» suavemente. No hace falta decirle cuándo frenar: la propia geometría del paisaje lo hace por él.
4. La tasa de aprendizaje: el mando más delicado
La tasa de aprendizaje controla cuánto te mueves en cada paso, y es probablemente el hiperparámetro que más quebraderos de cabeza da en todo el ML. Hay tres escenarios:
| Tasa de aprendizaje | Qué ocurre |
|---|---|
| Demasiado pequeña | El modelo baja bien, pero a paso de tortuga. Puede tardar muchísimo en llegar al fondo. |
| Demasiado grande | Los pasos son tan largos que el modelo se pasa de largo, rebota de una pared a otra del cuenco y diverge (el error crece en vez de bajar). |
| Adecuada | El modelo desciende rápido y suave, y se asienta limpiamente en el mínimo. |
La imagen mental es la de bajar unas escaleras: con pasos diminutos tardas una eternidad, pero si intentas bajarlas de tres en tres acabas en el suelo. Encontrar el equilibrio, normalmente probando varios valores, es una de las habilidades más prácticas que se aprenden en Machine Learning.
5. Intuición visual: bajar una colina con niebla
Esta es, para mí, la mejor forma de visualizarlo. Imagina que estás en una colina de noche, con niebla espesa y una linterna que solo ilumina el suelo justo delante de tus pies.
No ves el paisaje completo. No sabes dónde está exactamente el fondo. Lo único que percibes es:
- la inclinación del terreno donde estás pisando,
- hacia qué lado baja,
- y qué tamaño de paso quieres dar.
Con esa información limitada, tu estrategia es de sentido común:
- miras la pendiente bajo tus pies,
- das un paso en la dirección que desciende,
- vuelves a mirar la pendiente,
- das otro paso,
- repites.
Paso a paso, sin ver nunca el mapa completo, acabas llegando al fondo del valle. Eso es el Descenso del Gradiente: un algoritmo «ciego» que solo necesita conocer la pendiente local para encontrar el camino. Y lo mejor (gracias a que el paisaje de la regresión lineal es convexo, como vimos en la Parte 2) es que ese fondo es siempre el mismo, el mínimo global, da igual desde dónde empieces a bajar.
6. Por qué este algoritmo importa mucho más allá de la regresión
Aquí hay una pregunta honesta que quizá te estés haciendo: la Regresión Lineal tiene solución exacta (existe una fórmula cerrada que da los mejores y de un tirón, sin necesidad de iterar). Entonces, ¿para qué molestarse con el Descenso del Gradiente?
La respuesta es que la regresión lineal es la excusa perfecta para aprenderlo, porque casi ningún otro modelo tiene esa suerte. En cuanto el problema se complica, la fórmula mágica desaparece y solo queda una salida: bajar la colina paso a paso. El Descenso del Gradiente es el motor que entrena a:
- la regresión logística,
- las máquinas de vectores soporte (SVM),
- las redes neuronales,
- el deep learning,
- los transformers que hay detrás de los modelos de lenguaje actuales,
- y, en general, cualquier modelo entrenado con backpropagation.
Por eso no es exagerado decir que el Descenso del Gradiente es el motor de la IA moderna. Si entiendes bien este algoritmo en el caso simple de una recta, ya entiendes la mecánica esencial con la que aprende un modelo con miles de millones de parámetros. Cambia la escala, pero la idea es exactamente la misma.
7. Variantes del Descenso del Gradiente (vistazo rápido)
No todas las versiones del algoritmo dan el paso de la misma manera. La diferencia está en cuántos datos mira el modelo antes de actualizar los parámetros:
| Variante | Cuántos datos usa por paso | Carácter |
|---|---|---|
| Batch Gradient Descent | Todos los datos a la vez | Muy estable, pero lento y pesado en memoria con datasets grandes. |
| Stochastic Gradient Descent (SGD) | Un solo dato por actualización | Muy rápido, pero «ruidoso»: el camino al fondo zigzaguea. |
| Mini-Batch Gradient Descent | Pequeños lotes (32, 64, 128…) | El equilibrio perfecto entre velocidad y estabilidad. Es lo que usa el deep learning en la práctica. |
Una forma intuitiva de verlo: el batch es como estudiar el mapa entero antes de cada paso (seguro pero lento), el SGD es como dar un paso confiando solo en un vistazo rápido (rápido pero a veces tropiezas), y el mini-batch es el punto medio sensato que casi todo el mundo acaba usando. Más adelante en la serie dedicaremos espacio a estas variantes en detalle.
En resumen
- El Descenso del Gradiente es el algoritmo que reduce el error del modelo de forma iterativa.
- El gradiente indica hacia dónde aumenta el error; el modelo se mueve en la dirección contraria.
- La regla de actualización es una simple resta: valor actual − pendiente × tamaño del paso.
- La tasa de aprendizaje controla el tamaño del paso, y ajustarla bien es clave.
- Repitiendo el proceso, el modelo desciende hasta el mínimo global (garantizado, porque el paisaje es convexo).
- Este algoritmo es el motor que entrena casi todos los modelos modernos, desde la regresión logística hasta los transformers.