



Regresión Lineal (Parte 2)
La función de coste: cómo mide el modelo su error y por qué aprende minimizando
En la Parte 1 vimos la intuición: una recta, dos mandos (pendiente e intercepto) y un montón de puntos que queremos dejar lo más cerca posible de esa línea.
Pero nos dejamos en el tintero la pregunta más importante de todas:
¿Cómo sabe el modelo si lo está haciendo bien o mal?
Porque sin una forma de medir el error, no hay aprendizaje. Y sin aprendizaje, no hay Machine Learning. Así que hoy entramos en el corazón del modelo: la función de coste.
1. El error punto a punto: la distancia vertical
Cada punto de tus datos tiene dos caras:
- un valor real, que llamamos ,
- y una predicción del modelo, que llamamos .
La diferencia entre ambos es el error de ese punto:
Si la predicción cae por debajo del punto real, el error es positivo; si cae por encima, es negativo. Pero ese signo todavía no nos importa. Lo único relevante por ahora es que cada punto aporta su propio error.
2. El problema: los errores se cancelan
¿Y si simplemente sumáramos todos los errores tal cual?
Tendríamos un problema enorme: un error de +5 y otro de –5 se anularían entre sí, y el resultado daría cero. El modelo creería que todo va perfecto.
Pero no va perfecto. Va fatal. Necesitamos una forma de impedir que los errores se compensen unos con otros.
3. La solución elegante: elevar al cuadrado
Aquí entra el truco maestro. En lugar de sumar los errores, sumamos sus cuadrados:
¿Por qué elevar al cuadrado? Por tres razones que tienen mucho sentido:
- Los errores grandes duelen más. Un fallo de 10 no cuenta «10 veces más» que uno de 1: cuenta 100 veces más. Así obligamos al modelo a tomarse en serio los puntos que se quedan lejos.
- Evita las cancelaciones. Cualquier número al cuadrado es positivo, así que ya no hay manera de que un error compense a otro.
- Suaviza las matemáticas. Al elevar al cuadrado obtenemos una función «lisa» y derivable, algo que será clave para el descenso del gradiente de la Parte 3.
4. La función de coste completa: el MSE
Si juntamos todos los errores al cuadrado y sacamos la media, obtenemos la función de coste:
Esto tiene nombre propio:
✔️ MSE — Mean Squared Error (error cuadrático medio)
Es la métrica más usada en regresión, y básicamente resume en un solo número cómo de equivocado está el modelo con todos tus datos a la vez.
5. ¿Qué significa «minimizar» esta función?
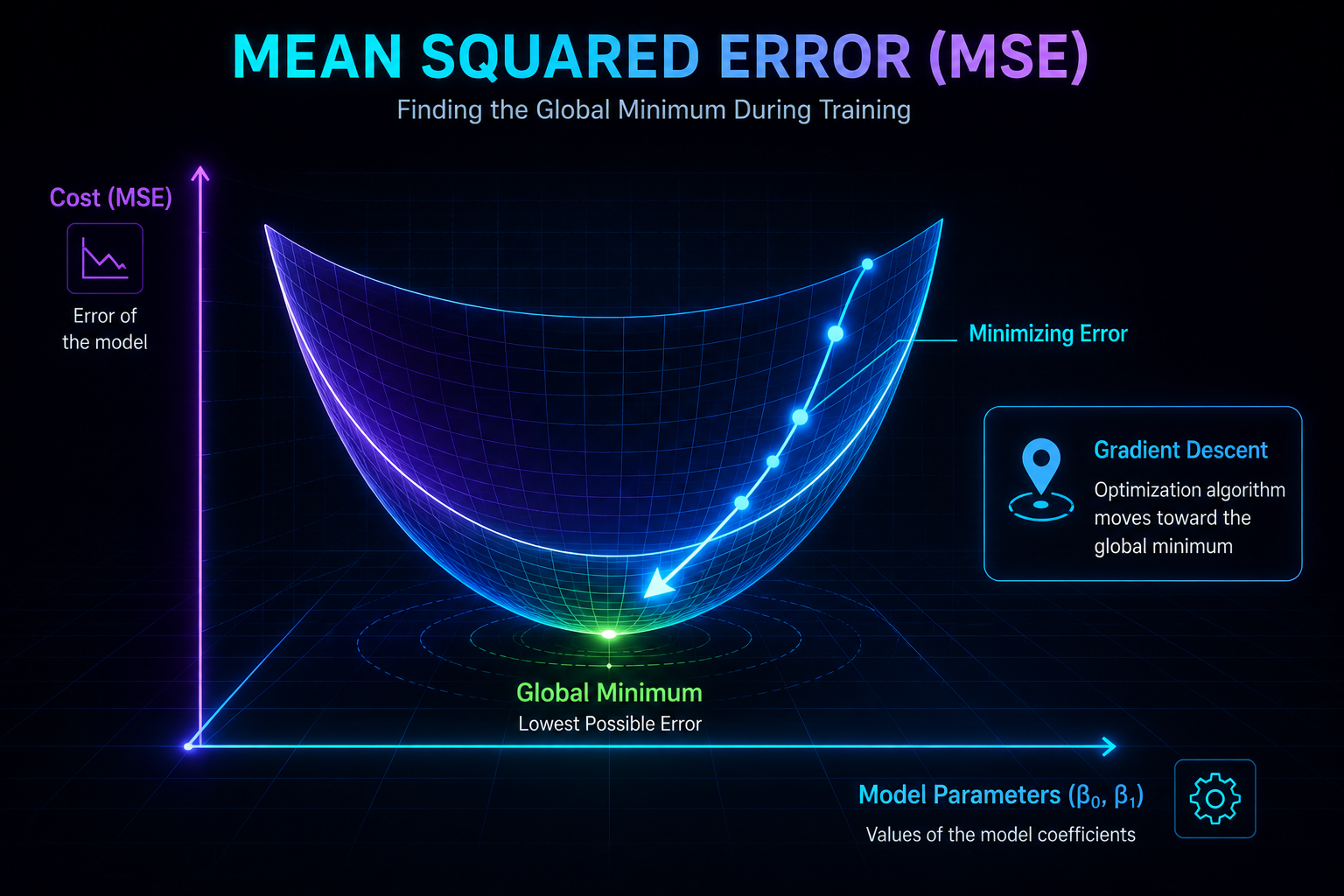
Aquí viene la parte bonita. Imagina que la función de coste es un paisaje: una colina suave, sin picos raros ni trampas.
Cada punto de ese paisaje corresponde a una combinación concreta de los dos mandos del modelo:
- , el intercepto,
- , la pendiente.
Y la altura en cada punto es el error (el MSE) que produce esa combinación. Con esta imagen en la cabeza, aprender es muy fácil de entender:
Aprender es encontrar el punto más bajo de ese paisaje.
Y ese punto más bajo es, ni más ni menos, la recta perfecta.
6. ¿Por qué este paisaje es tan especial?
Porque tiene una propiedad maravillosa: es convexo. En cristiano, eso significa que tiene forma de cuenco, y por tanto:
- no hay mínimos falsos,
- no hay valles escondidos donde quedarte atrapado,
- solo existe un único mínimo global.
Dicho de otra forma: empieces por donde empieces, si vas bajando la colina siempre acabarás en el mismo fondo. Esto convierte a la Regresión Lineal en uno de los modelos más estables y predecibles de todo el ML clásico.
7. ¿Y cómo baja el modelo por esa colina?
Aquí asoma la cabeza el protagonista de la Parte 3: ⭐ el descenso del gradiente.
La idea es muy sencilla:
- miras hacia dónde baja la colina,
- das un paso pequeño en esa dirección,
- vuelves a mirar,
- das otro paso,
- y repites hasta llegar al fondo.
Es como afinar una guitarra: ajustas, escuchas, ajustas, escuchas… hasta que suena perfecto. En la Parte 3 veremos exactamente cómo se calculan esos pasos.
8. ¿Por qué la función de coste es tan importante?
Porque introduce la idea central del aprendizaje supervisado:
Un modelo aprende minimizando una función de coste.
Y esto no es exclusivo de la regresión. Es el mismo principio que mueve a la regresión logística, las SVM, las redes neuronales, el deep learning, los transformers… cualquier modelo entrenado con gradiente.
La función de coste es, en el fondo, el termómetro del modelo. Sin ella, el modelo no tendría forma de saber si está mejorando o empeorando.
En resumen
- Cada punto aporta un error: .
- Los errores se elevan al cuadrado para evitar cancelaciones y penalizar más los fallos grandes.
- La función de coste MSE mide el error total del modelo en un solo número.
- Minimizar esa función equivale a encontrar la mejor recta.
- El paisaje del error es convexo: siempre hay un único mínimo.
- En la Parte 3 veremos cómo el modelo baja esa colina con el descenso del gradiente.