




Técnicas de selección de datos en machine learning: hold-out, cross-validation y más
La mayoría de los modelos de machine learning no fallan por el algoritmo… fallan porque la validación se hizo mal. La selección de datos es una de las etapas más importantes al construir un modelo predictivo. Consiste en dividir un dataset en distintos subconjuntos para entrenar, validar y evaluar el modelo de forma correcta. Aunque parece un paso básico, una mala división puede afectar seriamente la calidad de los resultados.
Si los datos no se separan bien, el modelo puede parecer muy preciso durante el entrenamiento, pero fallar cuando se enfrenta a información nueva. Por eso, elegir la estrategia adecuada de validación es fundamental para obtener métricas fiables y construir modelos que realmente generalicen.
¿Qué es la selección de datos?
La selección de datos es el proceso mediante el cual se decide qué parte del dataset se usará para entrenar el modelo y qué parte se reservará para validarlo o probarlo. Su objetivo es simular el comportamiento del modelo en un entorno real, donde tendrá que trabajar con datos que no ha visto antes.
Normalmente, el dataset se divide en tres conjuntos:
- Entrenamiento: el modelo aprende patrones.
- Validación: se ajustan hiperparámetros y se comparan modelos.
- Prueba: se mide el rendimiento final.
Esta separación permite evaluar si el modelo aprende patrones útiles o si simplemente memoriza los datos.
¿Por qué es importante validar bien los datos?
Una validación correcta permite medir la capacidad de generalización del modelo. Es decir, ayuda a saber si el sistema funcionará bien con datos nuevos.
Además, una buena estrategia de selección de datos permite:
- Detectar sobreajuste (overfitting).
- Evitar fuga de información (data leakage).
- Comparar modelos de forma justa.
- Obtener métricas más realistas.
- Mejorar la confianza en los resultados.
En proyectos reales, este paso es clave para evitar errores costosos en producción.
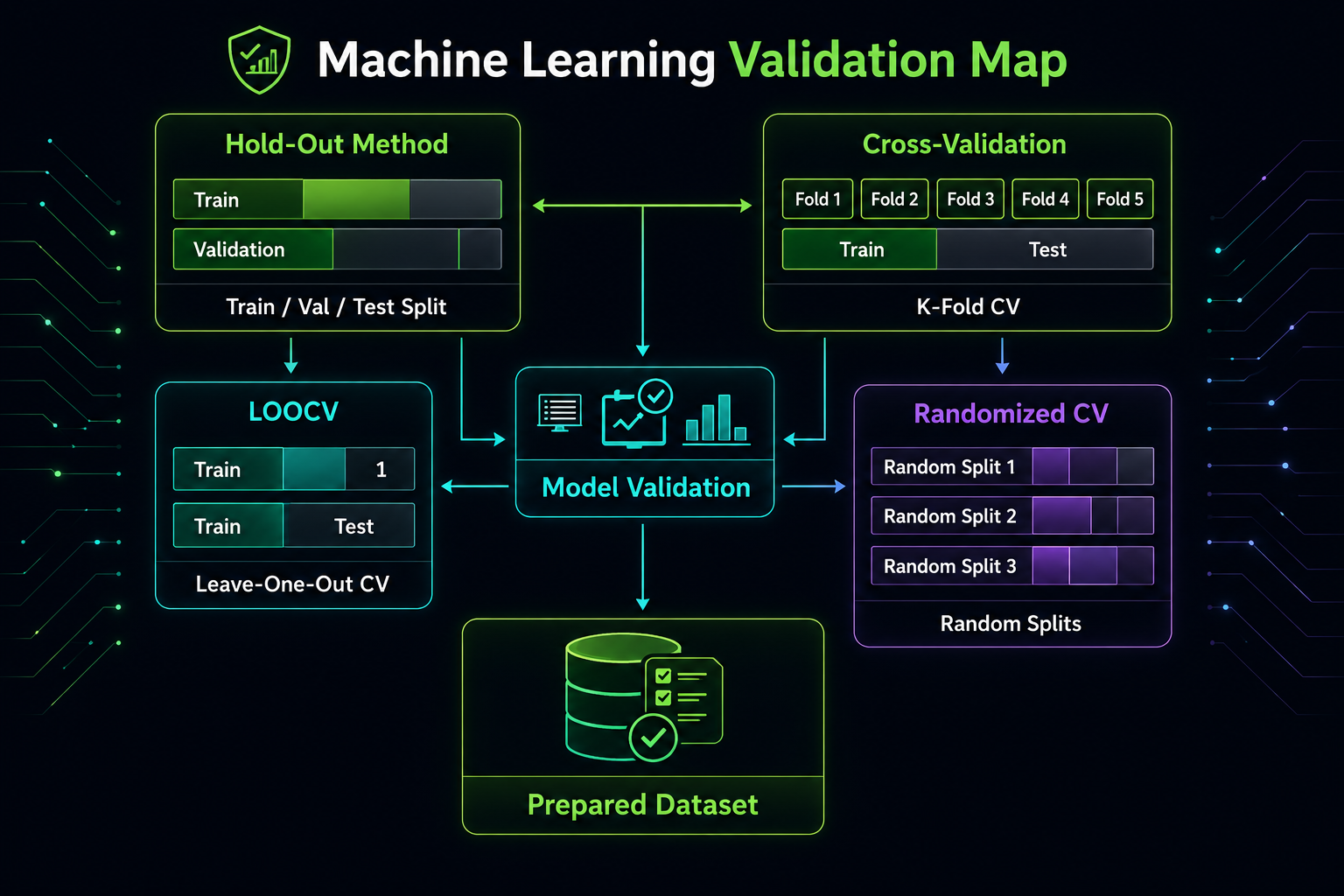
Principales técnicas de selección de datos
| Técnica | Descripción | Cuándo usarla |
|---|---|---|
| Hold-out | Divide el dataset en entrenamiento, validación y prueba. Simple y rápido. | Datasets grandes, evaluaciones rápidas. |
| Cross-validation | Divide los datos en k partes y repite el entrenamiento varias veces. | Datasets medianos o pequeños, evaluación estable. |
| LOOCV | Cada observación actúa como validación una vez. | Datasets muy pequeños. |
| Randomized CV | Varias divisiones aleatorias para medir estabilidad. | Cuando una sola partición puede sesgar resultados. |
Hold-out: la opción más simple
El método hold-out es rápido y fácil de implementar. Sin embargo, los resultados pueden depender mucho de la división inicial, por lo que no siempre es la opción más estable.
Cross-validation: una evaluación más robusta
La cross-validation reduce la dependencia de una sola partición y ofrece una estimación más estable del rendimiento del modelo. Es ideal cuando el dataset no es muy grande.
LOOCV: útil en datasets pequeños
Aprovecha casi todos los datos para entrenar, pero es costoso computacionalmente. Solo recomendable en datasets pequeños.
Randomized Cross-Validation: más flexibilidad
Permite evaluar la estabilidad del modelo frente a múltiples particiones aleatorias. Muy útil cuando se sospecha que una sola división puede no representar bien el comportamiento real.
Buenas prácticas al dividir datos
- Mantener la estratificación del target.
- Respetar el orden temporal en series de tiempo.
- Evitar que información del test llegue al entrenamiento.
- Separar claramente validación y prueba.
- Guardar la semilla aleatoria.
- Aplicar preprocesamiento solo sobre el conjunto de entrenamiento.
Errores frecuentes
- Entrenar y evaluar con los mismos datos.
- Ajustar hiperparámetros usando el conjunto de test.
- Ignorar el data leakage.
- Mezclar datos temporales sin respetar el orden.
Ejemplo práctico
Dataset de 10.000 registros para predecir churn:
- 70% entrenamiento
- 15% validación
- 15% prueba
Si el problema es desbalanceado, aplicar estratificación es obligatorio.
Conclusión
La selección de datos es mucho más que una simple partición. Es una parte esencial del proceso de entrenamiento y validación, porque permite medir el rendimiento real del modelo y evitar errores como el sobreajuste o la fuga de información.
Una estrategia de validación bien diseñada ayuda a construir modelos más confiables, más estables y mejor preparados para producción.
TL;DR
La selección de datos sirve para dividir correctamente el dataset y evaluar si un modelo realmente generaliza. Técnicas como hold-out, cross-validation y LOOCV ayudan a medir el rendimiento con mayor fiabilidad. Una buena validación evita sobreajuste, data leakage y métricas engañosas.