



Scikit‑Learn (Parte 1)
Estimators, Transformers y Predictors: la columna vertebral del Machine Learning clásico
En el post anterior recorrimos la historia completa del NLP y cómo llegamos a los LLMs modernos. Fue un viaje largo, lleno de arquitecturas, papers y momentos “ajá”.
Pero hoy toca volver a tierra firme.
Porque por muy potentes que sean los Transformers o los modelos generativos, el 80% de los problemas reales de empresa siguen resolviéndose con algo mucho más humilde, más rápido y, sobre todo, más explicable: Machine Learning clásico. Y la herramienta que domina ese terreno desde hace más de una década tiene nombre propio:
Scikit‑Learn.
El problema es que mucha gente lo usa como si fuera una caja negra: copian tres líneas de Stack Overflow, llaman a .fit() y rezan para que el modelo funcione. Y cuando algo se rompe, no saben dónde mirar.
Este post es la cura para eso.
Porque antes de construir un pipeline completo, necesitas entender las tres piezas fundamentales sobre las que está construida toda la librería:
- Estimators
- Transformers
- Predictors
Si entiendes esto, entiendes Scikit‑Learn. Y si entiendes Scikit‑Learn, entiendes el 80% del ML clásico.
Vamos paso a paso.
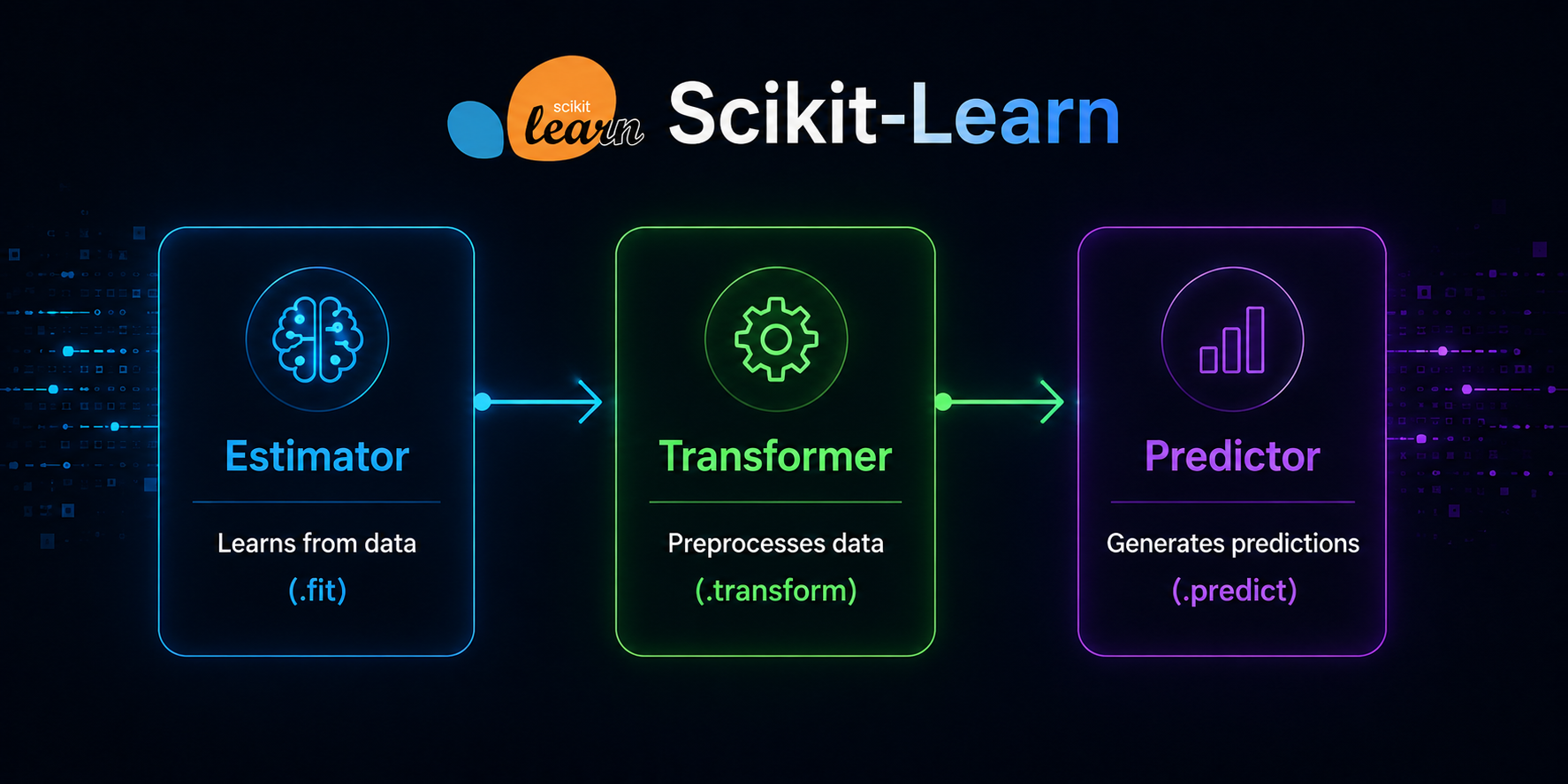
¿Qué es un Estimator? (El corazón de Scikit‑Learn)
En Scikit‑Learn, todo es un Estimator. Literalmente todo.
Un Estimator es cualquier objeto que implementa:
.fit(X, y)
Eso es todo. Si tiene .fit(), es un Estimator. No hay magia, no hay herencia oculta, no hay clases secretas. Es un contrato simple:
“Dame datos y aprenderé algo de ellos.”
Ejemplos de Estimators
StandardScaler()PCA()LogisticRegression()RandomForestClassifier()KMeans()
Todos ellos aprenden algo distinto:
- un modelo (coeficientes, pesos)
- una transformación (media y desviación estándar)
- una estructura (centroides)
- parámetros internos
La regla de oro
Si aprende algo con
.fit(), es un Estimator.
Y aquí va un detalle que nadie te cuenta al principio:
Todo lo aprendido se guarda en atributos que terminan en guion bajo (mean_, coef_, components_).
Esa convención es tu mejor amiga para depurar.
¿Qué es un Transformer? (El que transforma los datos)
Un Transformer es un Estimator que, además de .fit(), implementa:
.transform(X)
Es decir:
- Aprende algo con
.fit() - Aplica esa transformación con
.transform()
Ejemplos de Transformers
StandardScaler()→ normalizaMinMaxScaler()→ escalaOneHotEncoder()→ codificaPCA()→ reduce dimensionalidadTfidfVectorizer()→ vectoriza texto
¿Qué hace realmente un Transformer?
Piensa en él como un traductor:
Tu dataset habla un idioma que el modelo no entiende (escalas distintas, categorías en texto, demasiadas dimensiones). El Transformer lo traduce al idioma del algoritmo.
scaler = StandardScaler()
scaler.fit(X_train) # aprende media y desviación
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) # MISMA transformación
⚠️ Regla crítica: .fit() solo en train. .transform() en train y test.
Si haces .fit() sobre el test → data leakage.
Atajo útil
X_train_scaled = scaler.fit_transform(X_train)
Solo en train. Nunca en test.
¿Qué es un Predictor? (El que predice)
Un Predictor es un Estimator que implementa:
.predict(X)
Es decir:
- aprende con
.fit(X, y) - predice con
.predict(X)
Ejemplos de Predictors
LogisticRegression()RandomForestClassifier()SVC()KNeighborsClassifier()LinearRegression()
¿Qué devuelve un Predictor?
- una clase
- un valor numérico
- una probabilidad (
predict_proba())
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
Muchos modelos también implementan:
.score().predict_proba().decision_function()
Esa interfaz consistente es lo que hace que cambiar un modelo por otro sea trivial.
Cómo encajan juntos: el flujo natural del ML clásico
El flujo completo:
- Estimator → aprende algo
- Transformer → preprocesa
- Predictor → entrena y predice
Ejemplo típico:
scaler = StandardScaler()
model = LogisticRegression()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
Funciona, pero:
- es frágil
- es repetitivo
- es propenso a leakage
- es difícil de validar
- no escala cuando el pipeline crece
Por eso existen los Pipelines. Y los veremos en la Parte 2.
¿Por qué existen estas tres categorías?
Porque esta arquitectura permite:
- modularidad
- consistencia
- intercambiabilidad
- escalabilidad
- automatización
Gracias a esto puedes:
- cambiar un modelo sin tocar el resto
- encadenar pasos en un
Pipeline - validar todo con
cross_val_score - automatizar hiperparámetros con
GridSearchCV - preparar pipelines listos para producción
Scikit‑Learn no es casualidad. Es ingeniería bien hecha.
¿Qué viene ahora? (Parte 2)
El flujo completo de un Pipeline en Scikit‑Learn
Veremos:
- cómo unir Transformers + Predictors
- cómo usar
PipelineyColumnTransformer - cómo evitar leakage automáticamente
- cómo validar correctamente
- cómo preparar un pipeline para producción
- cómo integrarlo en tu proyecto AI Class
Ese será el post donde tu proyecto deja de parecer un notebook y empieza a parecer un sistema profesional.
TL;DR
- En Scikit‑Learn, todo es un Estimator.
- Un Transformer =
.fit()+.transform(). - Un Predictor =
.fit()+.predict(). - Los atributos aprendidos terminan en
_. - Esta arquitectura permite pipelines limpios, modulares y escalables.
- Entender esto es obligatorio antes de construir un pipeline completo.