



Preparación y Exploración de Datos (EDA) en Machine Learning
La mayoría de los proyectos de Machine Learning no fallan por el modelo… fallan porque nadie entendió bien los datos. El EDA es precisamente el punto donde un proyecto empieza a tener éxito o empieza a hundirse.
Una vez que el problema está bien definido y los objetivos del proyecto son claros, el siguiente paso crítico en cualquier iniciativa de Machine Learning es la preparación y exploración de datos, conocida habitualmente como Exploratory Data Analysis (EDA).
El EDA es el momento en el que realmente se empieza a entender la materia prima del modelo. No se trata solo de mirar columnas y gráficos, sino de descubrir qué información contiene el dataset, qué problemas arrastra, qué patrones aparecen y qué decisiones deben tomarse antes de entrenar cualquier algoritmo.
En la práctica, un buen EDA marca la diferencia entre un proyecto sólido y uno lleno de errores difíciles de corregir más adelante. No solo mejora el rendimiento del modelo: también ayuda a evitar sesgos, fuga de información, interpretaciones incorrectas y problemas en producción.
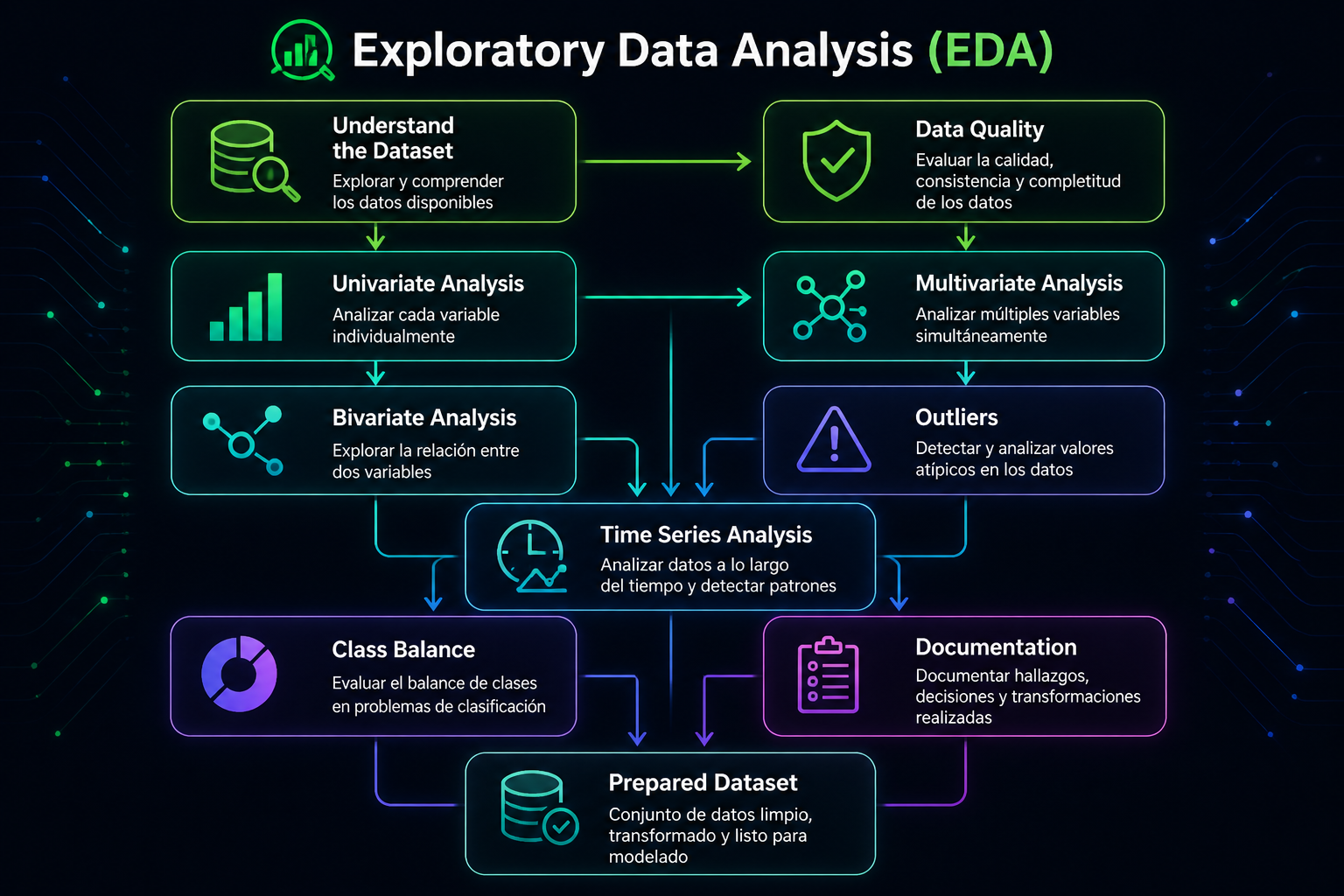
1. ¿Qué es el EDA y por qué es tan importante?
El Exploratory Data Analysis es el proceso de analizar, limpiar, transformar y comprender los datos antes de entrenar un modelo de Machine Learning.
Su propósito no es únicamente descriptivo. El EDA busca responder preguntas clave como:
- ¿Qué estructura tiene el dataset?
- ¿Qué tan completos y confiables son los datos?
- ¿Existen relaciones útiles entre variables?
- ¿Hay anomalías, errores o valores extremos?
- ¿El target está balanceado o sesgado?
- ¿Hay señales de fuga de información?
Un modelo siempre depende de la calidad de los datos que recibe. Por eso, un EDA bien hecho permite detectar problemas antes de que se conviertan en errores costosos.
Sin esta etapa, es fácil construir modelos que:
- aprenden ruido en lugar de patrones reales,
- muestran métricas engañosas,
- fallan al enfrentarse a datos nuevos,
- o toman decisiones basadas en información incompleta o incorrecta.
2. Comprender el dataset: estructura y contenido
El primer paso del EDA consiste en entender qué tipo de datos tenemos y cómo están organizados.
Antes de hacer cualquier transformación, conviene revisar:
- número de filas y columnas,
- tipo de variables: numéricas, categóricas, fechas, texto o identificadores,
- presencia de duplicados,
- valores faltantes,
- cardinalidad de las variables categóricas,
- rango, dispersión y distribución de las variables numéricas.
En esta fase también es importante hacerse preguntas de negocio y contexto:
- ¿Los datos representan realmente el problema que queremos resolver?
- ¿La muestra es suficiente para entrenar un modelo confiable?
- ¿Hay un sesgo evidente en la forma en que se recolectaron los datos?
- ¿Las variables tienen sentido desde una perspectiva operativa o empresarial?
Este análisis inicial ayuda a detectar errores estructurales que luego podrían afectar todo el pipeline.
3. Calidad de los datos: el enemigo silencioso
En muchos proyectos de Machine Learning, el principal problema no está en el modelo, sino en la calidad de los datos.
Los datasets reales suelen contener imperfecciones como:
- valores faltantes,
- registros duplicados,
- formatos inconsistentes,
- errores de captura,
- outliers extremos,
- columnas con muy poca variabilidad,
- variables con demasiados valores únicos,
- fechas mal interpretadas,
- o incluso fuga de información.
Uno de los errores más peligrosos es el data leakage, que ocurre cuando el modelo tiene acceso, directa o indirectamente, a información que no estaría disponible en el momento real de la predicción. Esto puede inflar artificialmente el rendimiento durante el entrenamiento, pero hacer que el modelo falle en producción.
Para tratar estos problemas, suelen aplicarse distintas estrategias:
- imputación de valores faltantes con media, mediana, moda o modelos más avanzados,
- eliminación de filas o columnas según el impacto del problema,
- normalización o estandarización,
- corrección de formatos,
- tratamiento de outliers mediante recorte o winsorización,
- revisión temporal para evitar fugas de información.
La elección de la estrategia depende del tipo de variable, de la cantidad de datos afectados y del impacto que ese problema tenga sobre el objetivo del modelo.
4. Análisis univariante, bivariante y multivariante
El EDA no se limita a mirar cada variable de forma aislada. También implica estudiar cómo se comportan entre sí.
Análisis univariante
El análisis univariante examina una sola variable a la vez.
Se usa para entender:
- la forma de la distribución,
- la dispersión,
- la presencia de valores extremos,
- la frecuencia de categorías,
- y el comportamiento general de cada feature.
Algunas visualizaciones útiles son:
- histogramas,
- boxplots,
- diagramas de barras,
- gráficos de densidad.
Este paso permite detectar variables con distribuciones extrañas, fuerte asimetría o poca variabilidad.
Análisis bivariante
El análisis bivariante estudia la relación entre dos variables.
Aquí se busca responder preguntas como:
- ¿Qué variables están relacionadas con el target?
- ¿Existen correlaciones fuertes entre variables?
- ¿Hay diferencias relevantes entre grupos o clases?
- ¿Una variable explica parcialmente el comportamiento de otra?
Para esto se suelen usar:
- scatterplots,
- tablas cruzadas,
- correlaciones,
- boxplots comparativos,
- gráficos de dispersión por clase.
Este nivel de análisis es especialmente útil para identificar variables predictivas, redundantes o poco informativas.
Análisis multivariante
El análisis multivariante observa la interacción entre varias variables al mismo tiempo.
Sirve para descubrir:
- patrones complejos,
- redundancias entre variables,
- relaciones no lineales,
- agrupaciones naturales,
- estructuras ocultas en los datos.
Algunas técnicas habituales son:
- matrices de correlación,
- mapas de calor,
- PCA,
- clustering exploratorio,
- pair plots.
Este paso es muy útil cuando el dataset tiene muchas variables y se necesita entender cómo se relacionan entre ellas antes de pasar al feature engineering.
5. Detección de outliers y anomalías
Los outliers son observaciones que se alejan notablemente del resto de los datos. No siempre son un error, pero siempre merecen atención.
Pueden:
- distorsionar medidas como la media,
- afectar modelos sensibles como regresión lineal, KNN o SVM,
- indicar errores de captura o registros defectuosos,
- o revelar comportamientos reales y relevantes.
Por ejemplo, un valor muy alto en una variable de facturación podría ser un error, pero también podría corresponder a un cliente de alto valor que el negocio necesita identificar.
Las técnicas más comunes para detectarlos son:
- boxplot e IQR,
- z-score,
- Isolation Forest,
- DBSCAN,
- visualización manual de distribuciones.
La decisión importante no es solo detectar el outlier, sino entender su origen:
- ¿es un error que debe corregirse?
- ¿es un caso excepcional que conviene conservar?
- ¿afecta al modelo de forma negativa?
- ¿debería tratarse de otra manera?
No todos los outliers deben eliminarse. En algunos casos, eliminarlos puede hacer que el modelo pierda información valiosa.
6. Análisis temporal, cuando aplica
En problemas con información temporal, el EDA debe incluir un análisis específico del comportamiento a lo largo del tiempo.
Esto es clave en casos como:
- forecasting,
- churn,
- fraude,
- demanda,
- mantenimiento predictivo,
- detección de anomalías.
En estos escenarios conviene estudiar:
- tendencias,
- estacionalidad,
- ciclos,
- cambios bruscos,
- anomalías temporales,
- comportamiento por ventanas de tiempo,
- variables rezagadas o lag features.
El análisis temporal también ayuda a detectar fuga de información, sobre todo cuando se mezclan registros de distintos momentos sin respetar el orden cronológico.
En muchos proyectos, este punto es decisivo para evitar modelos que parecen buenos en validación, pero fallan cuando se enfrentan a datos futuros.
7. Balance de clases y distribución del target
Cuando el target está desbalanceado, el problema cambia de forma importante.
Si una clase domina claramente sobre la otra, el modelo puede aprender a predecir siempre la clase mayoritaria y aun así mostrar una accuracy aparentemente aceptable. Por eso, en este contexto, la accuracy suele ser una métrica engañosa.
En lugar de eso, conviene revisar métricas como:
- precision,
- recall,
- F1-score,
- AUC-ROC,
- matriz de confusión.
También puede ser necesario aplicar técnicas como:
- oversampling,
- undersampling,
- SMOTE,
- ajuste de pesos de clase,
- umbrales de decisión personalizados.
El análisis del target es fundamental para entender si el problema está bien planteado y si las métricas elegidas reflejan realmente el valor del modelo.
8. Documentar el EDA: una etapa que muchos omiten
Un EDA profesional no termina en los gráficos. También debe dejar una trazabilidad clara de todo lo que se hizo.
Es recomendable documentar:
- qué problemas se detectaron,
- qué decisiones se tomaron,
- qué variables se eliminaron y por qué,
- cómo se imputaron los valores faltantes,
- qué riesgos se identificaron,
- qué hipótesis surgieron,
- qué supuestos se asumieron.
Esta documentación es importante por varias razones:
- facilita la reproducibilidad,
- ayuda en auditorías,
- mejora la colaboración entre equipos,
- aporta orden al pipeline,
- y es muy útil en contextos de MLOps o entornos regulados.
En proyectos reales, muchas veces el valor del EDA no está solo en el análisis en sí, sino en la claridad que deja para las siguientes fases.
9. Ejemplo práctico
Supongamos un proyecto para predecir churn en una plataforma SaaS.
El dataset contiene:
- 250.000 clientes,
- 40 variables,
- información de uso, facturación, soporte y comportamiento mensual.
Durante el EDA se detecta lo siguiente:
- 12% de valores faltantes en la variable “tiempo de respuesta del soporte”,
- 3 variables duplicadas,
- 1 variable con fuga de información,
- correlación fuerte entre “uso mensual” y “número de tickets”,
- outliers en “facturación mensual”,
- target desbalanceado con un 22% de churn,
- estacionalidad mensual en el uso del producto.
A partir de estos hallazgos se toman decisiones como:
- imputar valores faltantes con la mediana,
- eliminar variables duplicadas,
- quitar la variable con leakage,
- aplicar winsorización a los outliers,
- usar oversampling de forma moderada,
- crear variables temporales adicionales.
El resultado es un dataset más limpio, coherente y listo para la siguiente etapa: feature engineering y entrenamiento del modelo.
10. Conclusión
El EDA es una de las fases más importantes de todo el flujo de trabajo en Machine Learning.
Es el momento en el que se entienden los datos, se detectan problemas reales y se toman decisiones que afectan directamente al rendimiento del modelo final.
Un buen EDA permite:
- reducir errores,
- mejorar la calidad del dataset,
- evitar fuga de información,
- encontrar patrones relevantes,
- orientar el feature engineering,
- acelerar el desarrollo,
- y aumentar las probabilidades de éxito en producción.
Sin un EDA sólido, incluso el mejor modelo puede quedar limitado por datos mal entendidos o mal preparados.
Próximo artículo
En el siguiente post veremos Feature Engineering, es decir, cómo transformar datos brutos en variables más útiles para mejorar el rendimiento del modelo.
Si quieres, puedo hacer una de estas tres cosas con este texto:
- convertirlo en una versión más SEO-friendly para blog,
- darle un tono más académico o corporativo,
- o dejarlo listo como un artículo final pulido para publicar.
En resumen: el contenido ya está bien planteado; lo que más gana al desarrollarlo es darle más fluidez, ejemplos y transiciones para que se lea como un artículo completo y no como apuntes.