




Data Leakage: El Enemigo Silencioso que Destruye tus Modelos de Machine Learning
Hoy entramos en uno de los problemas más peligrosos y menos visibles del ML real: el data leakage.
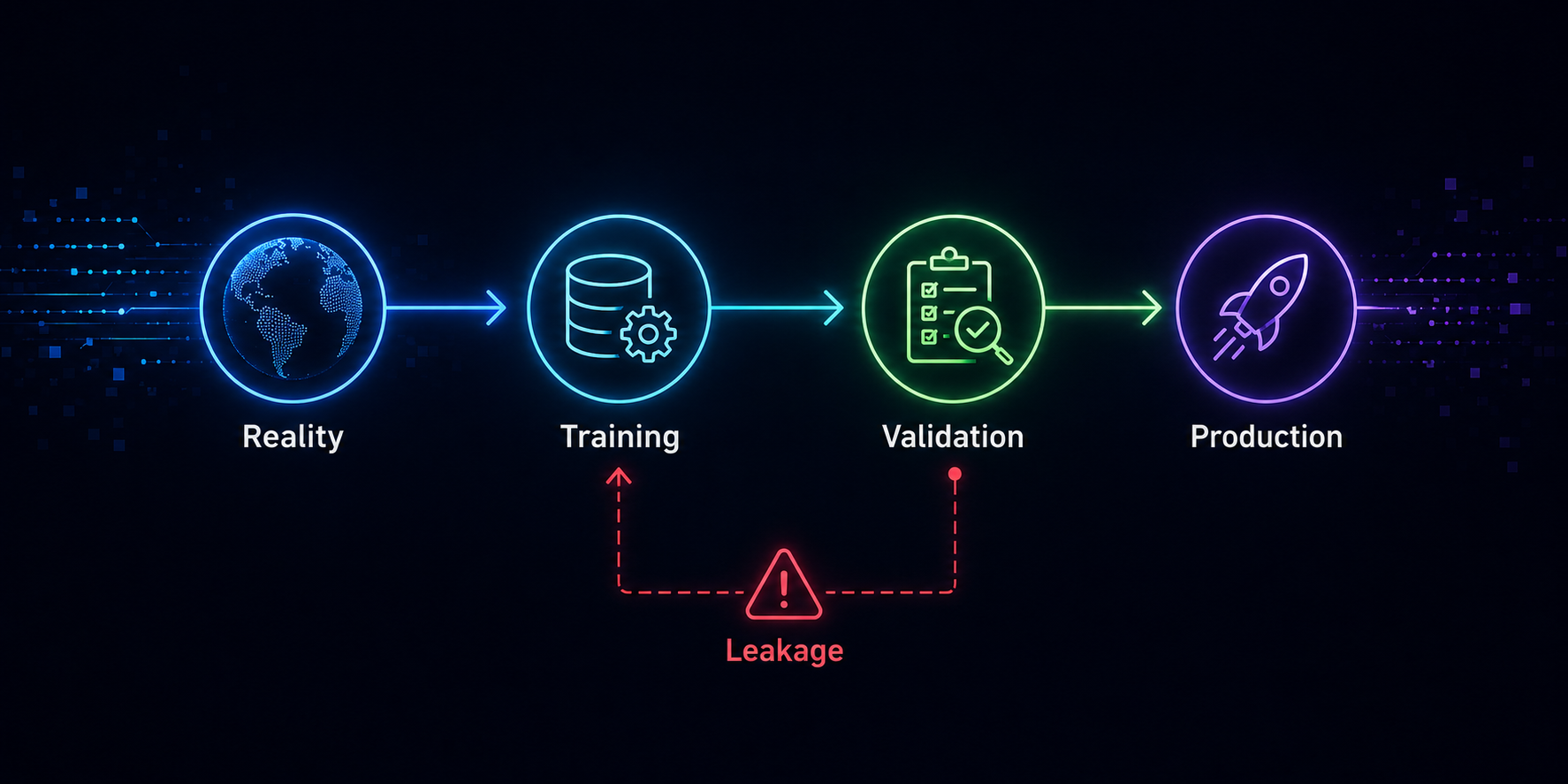
Un modelo de predicción de fraude con 99.8% de precisión en validación. El equipo celebra. Se despliega a producción. Resultado: 52% de precisión.
¿Qué pasó?
Una columna llamadatransaction_reversedque solo existía después de detectar el fraude. Data leakage en estado puro.
Si alguna vez has entrenado un modelo que parecía perfecto en validación pero se derrumbó en producción, es muy probable que el culpable fuera este fenómeno.
El data leakage no lanza warnings. No rompe el código. No genera excepciones.
Pero destruye la capacidad de generalización de un modelo. Y lo peor: puede pasar desapercibido incluso para equipos experimentados.
¿Qué es exactamente el data leakage?
El data leakage ocurre cuando información del futuro o del conjunto de validación se filtra en el entrenamiento del modelo.
Es decir, el modelo aprende patrones que no existirán en un escenario real.
Por eso, durante la validación:
- La precisión parece altísima
- El AUC se dispara
- La pérdida cae en picado
Pero en producción:
- El rendimiento se desploma
- Las predicciones se vuelven inconsistentes
- El modelo deja de ser útil
En otras palabras: el modelo hace «trampa» sin que nos demos cuenta.
Los 4 tipos de data leakage más comunes
1. Leakage por filtración temporal
El más peligroso y el más frecuente.
Ocurre cuando el modelo usa información del futuro para predecir el pasado.
Ejemplo concreto:
Imagina predecir si un cliente comprará en marzo usando como featuregasto_promedio_trimestre_1. Si ese trimestre incluye marzo, estás usando el futuro para predecir el presente.
El modelo aprende que «gasto alto en Q1 = compra en marzo» porque marzo está dentro de Q1. En producción, cuando predices en marzo, no tienes el gasto completo del trimestre.
Otro caso típico:
# ❌ Incorrecto
df['avg_purchase_next_30_days'] = df.groupby('user_id')['amount'].rolling(30).mean()
# ✅ Correcto
df['avg_purchase_last_30_days'] = df.groupby('user_id')['amount'].shift(1).rolling(30).mean()2. Leakage por preprocesamiento incorrecto
Sucede cuando aplicamos transformaciones antes de dividir los datos.
Operaciones peligrosas:
- Normalización
- Estandarización
- Imputación de valores faltantes
- Selección de características
- Encoding de variables categóricas
Si estas operaciones se hacen sobre todo el dataset, el modelo «ve» información del conjunto de validación.
❌ Incorrecto:
# Normalizar TODO el dataset primero
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test = train_test_split(X_scaled)✅ Correcto:
# Dividir primero, transformar después
X_train, X_test = train_test_split(X)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # fit_transform en train
X_test_scaled = scaler.transform(X_test) # solo transform en testLa diferencia: en el enfoque correcto, el scaler solo «aprende» de los datos de entrenamiento.
3. Leakage por variables altamente correlacionadas
Variables que contienen indirectamente la respuesta.
Red flags de variables sospechosas:
- Nombres que incluyen «final», «resultado», «status_actual», «cancelado»
- Correlación > 0.95 con el target
- Valores que solo existen después del evento objetivo
- Columnas que un humano no tendría disponibles al momento de predecir
Ejemplo real:
Predecir churn usando una columnafecha_de_cancelacion. Si esa columna tiene valor, el cliente ya hizo churn. Es como predecir si va a llover mirando si el suelo está mojado.
4. Leakage por duplicados o registros relacionados
Muy común en:
- Datos médicos (mismo paciente, múltiples visitas)
- Transacciones (mismo usuario, múltiples compras)
- Series temporales
- Datasets con múltiples filas por entidad
Si un mismo usuario aparece en train y test, el modelo memoriza patrones específicos de ese usuario en lugar de aprender patrones generales.
Solución:
# Dividir por entidad, no por filas
from sklearn.model_selection import GroupShuffleSplit
splitter = GroupShuffleSplit(test_size=0.2, random_state=42)
train_idx, test_idx = next(splitter.split(X, y, groups=df['user_id']))Cómo detectar data leakage
Señales de alarma
- Precisión sospechosamente alta (>95% en problemas complejos del mundo real)
- Una variable domina el modelo (feature importance >80%)
- Rendimiento se desploma en producción (>15% de caída)
- Validación cruzada da resultados muy inconsistentes
- El modelo funciona «demasiado bien» con muy pocos datos
Test rápido
Elimina las top 3 variables más importantes de tu modelo.
Si el rendimiento colapsa completamente (cae >50%), investiga esas variables a fondo. Es probable que contengan leakage.
Preguntas clave para cada feature
- ¿Esta variable existiría en el momento de la predicción?
- ¿Contiene información del futuro?
- ¿Es un proxy directo de la etiqueta?
- ¿Cómo se calculó? ¿Incluye datos posteriores al evento?
Cómo evitarlo: las reglas de oro
1. Divide primero, transforma después
El orden correcto:
- Train/Test split
- Preprocesamiento ajustado solo con train
- Aplicar transformaciones al test usando los parámetros del train
Usa pipelines para automatizarlo:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# El pipeline garantiza el orden correcto
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier())
])
# fit solo ve los datos de train
pipeline.fit(X_train, y_train)
# predict usa los parámetros aprendidos de train
y_pred = pipeline.predict(X_test)2. Respeta la temporalidad
En series temporales:
❌ Nunca hagas esto:
from sklearn.model_selection import KFold
# KFold mezcla pasado y futuro
kfold = KFold(n_splits=5, shuffle=True)✅ Haz esto:
from sklearn.model_selection import TimeSeriesSplit
# TimeSeriesSplit respeta el orden temporal
tscv = TimeSeriesSplit(n_splits=5)Reglas para time series:
- Nunca mezclar pasado y futuro
- Usar splits cronológicos
- Features con rolling windows: asegúrate de que no incluyen el punto a predecir
- Siempre ordenar por tiempo antes de dividir
3. Revisa las variables con sentido de negocio
No confíes ciegamente en la importancia de features. Pregúntate:
- ¿Esta variable existiría en el momento de la predicción?
- ¿Cómo se recolecta en la realidad?
- ¿Hay un delay entre el evento y la disponibilidad del dato?
Ejemplo real de e-commerce:
Predecir si un usuario comprará mañana usandoitems_in_cart_tomorrow. Obviamente, mañana no ha llegado aún.
4. Evita duplicados entre train y test
Especialmente crítico en:
- Datos de usuarios (divide por
user_id) - Logs de aplicaciones (divide por
session_id) - Transacciones financieras (divide por
customer_id) - Datos clínicos (divide por
patient_id)
5. Valida con datos «fuera del tiempo»
Si tu modelo se desplegará en enero 2027, valídalo con datos de diciembre 2026 que no usaste en entrenamiento.
Simula el escenario real: entrena con pasado, predice el futuro.
Casos reales con soluciones
Caso 1: Predicción de churn
❌ Incorrecto:
df['dias_desde_ultima_actividad'] = (datetime.now() - df['last_activity']).days✅ Correcto:
# Usar una fecha de corte fija (la fecha en que harías la predicción)
fecha_corte = '2026-01-01'
df['dias_desde_ultima_actividad'] = (fecha_corte - df['last_activity']).daysCaso 2: Imputación de valores faltantes
❌ Incorrecto:
# Imputar con la media global
df['age'].fillna(df['age'].mean(), inplace=True)
X_train, X_test = train_test_split(df)✅ Correcto:
X_train, X_test = train_test_split(df)
# Calcular la media solo del train
mean_age = X_train['age'].mean()
# Aplicar a ambos conjuntos
X_train['age'].fillna(mean_age, inplace=True)
X_test['age'].fillna(mean_age, inplace=True)Caso 3: Normalización con StandardScaler
❌ Incorrecto:
scaler = StandardScaler()
df[['feature1', 'feature2']] = scaler.fit_transform(df[['feature1', 'feature2']])
X_train, X_test = train_test_split(df)✅ Correcto:
X_train, X_test = train_test_split(df)
scaler = StandardScaler()
X_train[['feature1', 'feature2']] = scaler.fit_transform(X_train[['feature1', 'feature2']])
X_test[['feature1', 'feature2']] = scaler.transform(X_test[['feature1', 'feature2']])Caso 4: Feature engineering con agregaciones
❌ Incorrecto:
# Agregar todas las transacciones del usuario (incluyendo futuras)
df['user_total_spent'] = df.groupby('user_id')['amount'].transform('sum')✅ Correcto:
# Solo agregar transacciones anteriores a la fecha de corte
df = df.sort_values('transaction_date')
df['user_total_spent'] = df.groupby('user_id')['amount'].cumsum().shift(1)Checklist antes de entrenar tu modelo
Usa esta lista de verificación antes de cada entrenamiento:
- ¿Dividí los datos ANTES de cualquier transformación?
- ¿Todas mis features existirían en el momento de predicción?
- ¿Usé
.fit_transform()solo en train y.transform()en test? - ¿Verifiqué que no hay duplicados o entidades compartidas entre train/test?
- ¿Las métricas son «demasiado buenas para ser verdad»?
- ¿Revisé las top 5 features más importantes con sentido de negocio?
- ¿Usé
TimeSeriesSplitsi trabajo con series temporales? - ¿Implementé todo en un Pipeline para evitar errores manuales?
- ¿Validé con datos completamente fuera del período de entrenamiento?
Herramientas que ayudan a prevenir leakage
Pipelines y automatización:
sklearn.pipeline.Pipeline– garantiza el orden correcto de operacionesfeature-engine– transformadores que respetan train/test splitcategory_encoders– encoding seguro de variables categóricas
Validación temporal:
sklearn.model_selection.TimeSeriesSplit– para series temporalessklearn.model_selection.GroupShuffleSplit– para datos agrupados
Detección:
- Analiza la distribución de features entre train/test
- Compara feature importance con conocimiento del negocio
- Monitorea el rendimiento en producción vs validación
Conclusión
El data leakage es uno de los errores más críticos en Machine Learning porque:
- No es evidente a simple vista
- Produce métricas engañosas
- Invalida completamente un modelo en producción
- Es extremadamente común, incluso en equipos experimentados
La buena noticia: se puede evitar siguiendo prácticas sólidas.
La regla de oro: Si tus métricas parecen demasiado buenas, probablemente lo sean. Investiga.
Un modelo sin leakage es un modelo que puede sobrevivir en producción. Y esa es la única métrica que realmente importa.
Recursos adicionales:
scikit-learn.org
- Paper: «Leakage in Data Mining: Formulation, Detection, and Avoidance» (Kaufman et al., 2012)
feature-engine.readthedocs.io
¿Has detectado data leakage en tus proyectos? ¿Qué otros tipos has encontrado? Comparte tu experiencia en los comentarios.
“Un modelo que generaliza es un modelo que vive.
Y el data leakage es su enemigo más silencioso.”