



Validación cruzada aleatoria: qué es, cómo funciona y cuándo usarla en Machine Learning
Cuando entrenamos un modelo de Machine Learning, no solo importa cómo dividimos los datos, sino también cómo variamos esas divisisiones para obtener una evaluación más robusta. La validación cruzada clásica (k‑fold) es una gran herramienta, pero a veces necesitamos algo más flexible y menos rígido. Ahí es donde entra la validación cruzada aleatoria.
¿Qué es la validación cruzada aleatoria?
La Randomized Cross‑Validation consiste en generar múltiples particiones aleatorias del dataset y evaluar el modelo en cada una de ellas. En lugar de dividir los datos en k folds fijos, se crean N divisiones aleatorias independientes, cada una con su propio conjunto de entrenamiento y validación.
Es similar al método hold‑out, pero repetido muchas veces y con particiones distintas en cada iteración.
¿Por qué usarla?
Porque introduce variabilidad controlada. Cada división aleatoria ofrece una perspectiva distinta del rendimiento del modelo, lo que permite:
- Medir la estabilidad del modelo.
- Detectar dependencias de particiones específicas.
- Obtener métricas más representativas en datasets medianos o ruidosos.
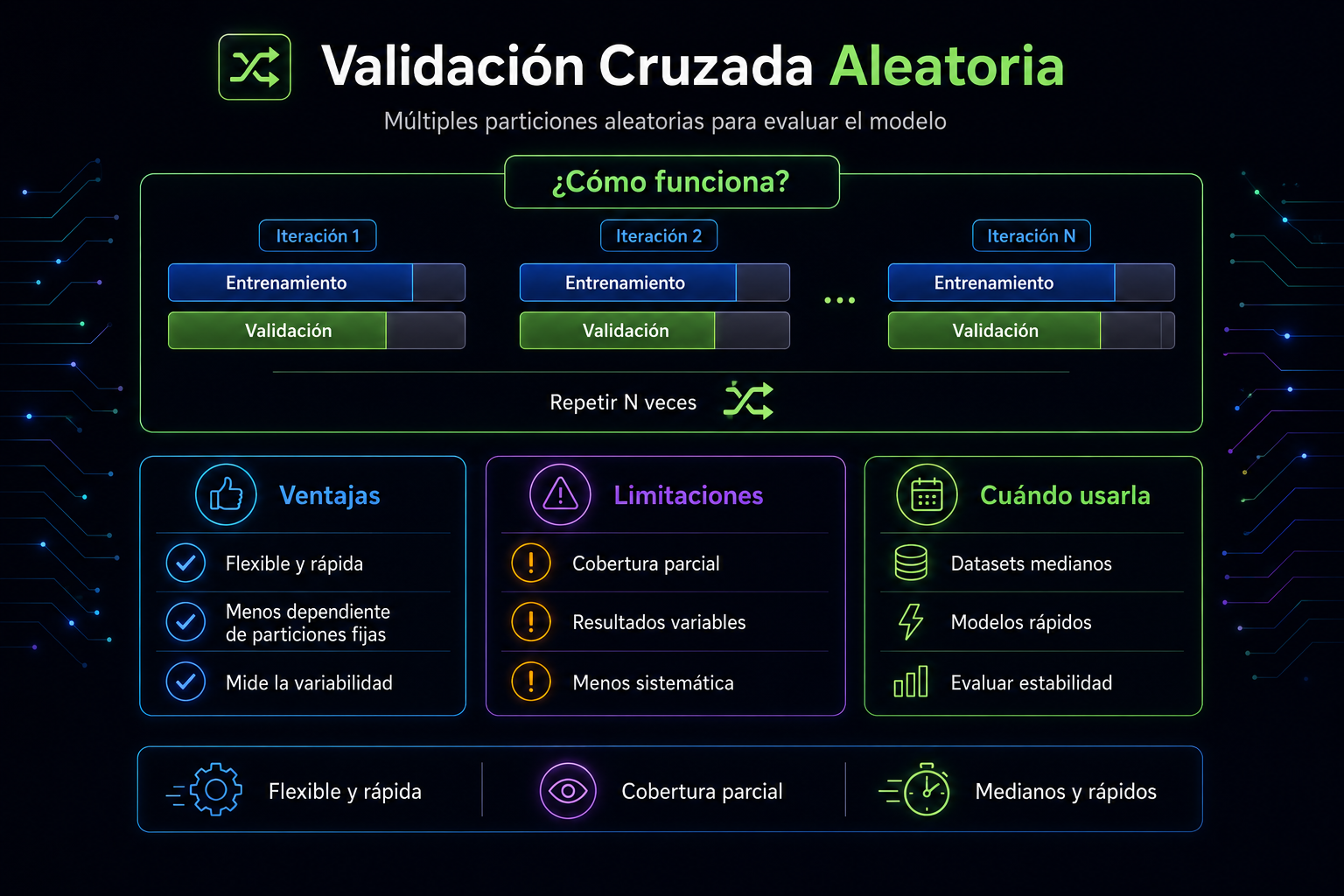
Ventajas
- Flexible: no depende de un número fijo de folds.
- Rápida: más ligera que LOOCV y, en muchos casos, más rápida que k‑fold.
- Robusta: al repetir varias particiones aleatorias, reduce el riesgo de una división desafortunada.
- Ideal para modelos rápidos: permite muchas iteraciones sin gran coste.
Limitaciones
- No garantiza cobertura completa: algunas observaciones pueden no aparecer nunca en validación.
- Resultados variables: dependen del número de repeticiones y de la semilla aleatoria.
- Menos sistemática que k‑fold: no asegura un uso equilibrado de todas las muestras.
¿Cuándo conviene usarla?
Esta técnica es especialmente útil cuando:
- El dataset es mediano y no quieres el coste computacional de k‑fold.
- El modelo es rápido de entrenar y puedes permitirte varias repeticiones.
- Quieres medir la variabilidad del rendimiento.
- Buscas una alternativa más flexible al hold‑out tradicional.
Ejemplo conceptual
Si eliges 10 repeticiones con un split 80/20:
- Cada iteración genera una partición aleatoria 80% entrenamiento / 20% validación.
- El modelo se entrena y evalúa 10 veces.
- Las métricas finales se obtienen promediando los resultados.
Comparación con otras técnicas
| Técnica | Idea | Ventaja | Limitación | Mejor escenario |
|---|---|---|---|---|
| Hold‑out | Una sola división | Rápido | Inestable | Datasets grandes |
| K‑Fold CV | K divisiones fijas | Estable | Más costoso | Datasets pequeños/medianos |
| Randomized CV | Varias divisiones aleatorias | Flexible y rápida | Menos sistemática | Datasets medianos |
| LOOCV | Dejar uno fuera | Máxima precisión | Muy lento | Datasets muy pequeños |
Conclusión
La validación cruzada aleatoria es una técnica intermedia entre el hold‑out y la cross‑validation clásica: más flexible que k‑fold, más robusta que una sola partición y menos costosa que LOOCV.
Es una técnica que muchos pasan por alto, pero que puede marcar la diferencia en proyectos reales. Si buscas un equilibrio entre rapidez, variabilidad y robustez, es una excelente opción para evaluar tus modelos de Machine Learning.
TL;DR
- Randomized CV = múltiples particiones aleatorias.
- Más flexible que k‑fold, más robusta que hold‑out.
- Ideal para datasets medianos y modelos rápidos.
- No garantiza cobertura completa, pero ofrece buena estabilidad.